Filter by Keywords

10 Free Incident Report Templates in ClickUp Docs, Word, and Excel
Praburam Srinivasan
Growth Marketing Manager
February 13, 2024
Start using ClickUp today
- Manage all your work in one place
- Collaborate with your team
- Use ClickUp for FREE—forever
As much as we all hate to admit it, accidents happen. 🤷🏼♀️
And when it comes down to it, accountability and honesty are always the best policies—but that’s a blog for another time! No matter how severe the incident was or even if something major was just narrowly missed, you must record and report the situation.
It sounds a little scary, but it doesn’t have to be.
Incident reporting doesn’t just keep track of your HR department’s top KPI , it ensures that history doesn’t repeat itself and keeps your team operating efficiently, and most importantly, safely .
Your safety is every company’s top priority, so there’s a lot riding on incident reports to tell the entire story including key details, dates, parties involved, circumstances, and follow-ups.
Plus, many companies report to even bigger companies to prove how they’re following safety protocols across the board when it comes to security, first aid, exposure, or damage.
An incident report form or template makes this process significantly easier. These tools can ease your mind in stressful situations by making sure every incident report is filled out providing ways to improve your worklife going forward.
And to find your next incident report form or template, you’ve come to the right place. 🙂
We’ll guide you through the top incident reporting FAQs, top template features to look for, and provide 10 free examples for ClickUp, Word, Excel, and more. 🙌🏼
What is an Incident Report Template?
What makes for a good incident report template, 1. clickup employee incident report template, 2. clickup incident action plan template, 3. clickup security incident report template, 4. clickup it incident report template, 5. clickup simple after action report template, 6. clickup service incident report template, 7. clickup end of day report template, 8. clickup corrective action plan template, 9. microsoft word incident report template, 10. excel incident report template.
Let’s say your team nearly misses a major accident at work. Luckily, no one was hurt—but you’re all a bit shaken and the incident could’ve been avoided altogether.
After everyone’s nerves are settled and cups of water have been distributed, your manager will fill out an incident report detailing exactly what happened.
Instead of opening a blank document, incident management software and a customizable report template will guide you through the next steps.
An incident report form or template is a pre-built and formatted document for managers to record incidents including damage, injuries, workplace safety, close calls, and more. These templates are typically followed from top to bottom and cover the situation’s who, what, where, when, why, and how .
These documents are often stored and tracked using designated HR software to keep monitor HR KPIs over time or even shared with other companies that oversee workplace safety.
All incident reports must include a lot of key details, but no two templates look alike. The same goes for their formatting! Your incident reporting process may revolve around documents , spreadsheets, or forms to gather the necessary information.
Still, there are a few essential features to look for in your next incident report form or template to make sure safety stays at the forefront of your business:
- Rich formatting and styling to support multiple sections, nested pages, tables, or embedded media in the report.
- Collaboration features like live editing with multiple team members, comments within the template to communicate approvals, and @mentions.
- Security, permissions, and sharing to make sure sensitive information stays between the right people.
- Integrations to extend the functionality of your template, bring in additional context through embedding, and keep your reports secure and organized among the rest of your work.
10 Incident Report Templates
Now that we’ve covered the basics, let’s put your newfound knowledge to the test!
Knowing the qualities of top incident report templates and their role in company safety, comb through some of the best templates on the market today—and access them all directly from this article!
Here are the top 10 free incident report templates to improve safety and security at work for ClickUp , Word, and Excel.

An Employee Incident Report is an important document to file for any incident or incident-related activity involving a current or former employee at a business. It’s commonly completed by the company’s Human Resources (HR) department.
Typically these reports are used to record relevant details such as the date, time, incident type, incident location, parties involved, incident description, and any action taken as a result of the incident.
The ClickUp Employee Incident Report Template will help you create an incident report quickly and standardize the process for recording employee incidents. The Doc breaks down an incident reporting process that’s easy to navigate. These documents can be used for incident tracking, incident analysis, and incident prevention purposes.

An Incident Action Plan (IAP) is a document outlining immediate plans to respond to an incident or emergency. Incident action plans include details such as resources, operational period information, safety considerations, communication protocols , and incident tracking methods .
By using the ClickUp Incident Action Plan Template as a starting point, businesses can save time and ensure that all necessary information is included in each IAP they develop. This will help companies create reliable records of incident-related activity and put effective strategies in place!
The template includes color-coded sections to capture all the information required for approval:
- Situation Summary : brief summary of the Incident Action Plan
- Execution Plan : Objectives and strategies
- Incident Team Contact Information : Methods of contact for personnel on scene
- Incident Organization List : Operations , Planning , Logistics , and Finance teams
- Incident Assignment List : Tasks for supervisors and team members
- Map/Situation Summary : Incident site/region or other graphics
Incident Plan Approval : Submitted by , Date Submitted , and Signature

A security incident report form captures all the details about any incident or incident-related activities. It also includes key indicators such as urgency level and severity of the incident. This is especially important for high-risk incidents, such as workplace accidents, injuries sustained, and medical treatment situations.
Security incident reports will help analyze the overall effectiveness of an organization’s security systems and processes. By understanding how incidents occur and how they can be prevented in the future, companies can work towards creating more secure environments for their employees.
Directly share the ClickUp Security Incident Report Template URL among your team or export it for paper filing purposes. You can even protect your ClickUp Docs using the privacy and edit controls to prevent unwanted changes to the report information! 🔐
By tracking all incidents with accurate data points over a period of time, enterprises can gain a better understanding of security trends within their environment and develop effective strategies for addressing them in the future.
Learn how to reduce cyber security risks in remote project management !

An IT incident report is an internal document companies use to record and monitor IT incident-related information. By having comprehensive incident reports that are detailed and accurate, companies can identify incident trends which help them improve the response process and ensure compliance with legal requirements.
Additionally, these documents help IT teams collaborate more effectively on incident response efforts while improving containment and resolution times. In turn, organizations save reliable records of all past incidents associated with their environment which can be used to assess current security posture and plan for future threats accordingly.
The ClickUp IT Incident Report Template includes a detailed description, a checklist, subtasks, and Custom Fields any manager can use to create a thorough, effective reporting of an IT incident. This task template provides a structure for developing your report, but it’s completely customizable to fit your organizational processes and procedures!

An After-Action Report is a strategic document used to evaluate and review the success or failure of a project, activity, or event. It is designed to assess both the positive and negative results to analyze what went well and what could have been improved.
And with the ClickUp Simple After Action Report Template , you’ll cover all your bases with this detailed Doc. The report is divided into four subpages:
- Exercise Overview
- Core Capability Analysis
- Core Capability Report
- Improvement Plan
Whether you’re new to After Action Reports or need new ideas to make an impact on stakeholders, this is a great template to work through on your own or with your team!

A service report is a document detailing the activities and result of a service. A properly completed service report can be an invaluable tool for businesses and customers. It provides documentation of the services performed, which helps businesses track service history and maintain customer satisfaction. For customers, it acts as a record of the service that was performed and any changes or improvements made.
The ClickUp Service Report Template is designed to enhance the description process with embedding features, rich text editing, media file sharing, and more. The task template is prebuilt with the general details of an acceptable service report, but feel free to customize it even further so it meets your organization’s standards.
Discover the top issue tracking software to resolve customer concerns!

An End of Day Incident Report is an incident document generated at the end of each business day. These reports contain detailed incident information such as incident severity level, impacted assets or systems, involved personnel or teams, and an incident timeline.
Additionally, these reports provide insight into the incident resolution process, corrective actions taken by the organization, and any lessons learned . They also allow organizations to gain an understanding of their incident trends over a longer period of time and plan for threats in advance.
The ClickUp End of Day Report Template is a great starter option for businesses looking to identify gaps or weaknesses in response processes that should be addressed in order to improve containment and resolution times in the future. It comes with a self-assessment for the employees to rate their productivity, their backlogs, and tasks for the next day.
Check out the Getting Started guide for tips and examples to make it your own!

A Corrective Action Plan is a set of steps designed to identify, correct, and prevent the recurrence of potential or existing errors and problems. This plan outlines the strategies that an organization should take in order to remediate the incident and restore normal operations. The plan typically includes actions such as root cause analysis , data documentation, risk management practices, and incident closure activities.
It’s sometimes a time-consuming process to get everyone on the same page. Especially when information can be used for regulatory reporting purposes and court cases if needed. Try the ClickUp Corrective Action Plan Template to align communication and tasks to save time!
The main elements of a CAP in this Whiteboard template are organized to shorten the time it takes from identifying an incident to implementing a solution:
- Areas for Improvement : Identify the fields around your business operations or team performance that needs changes and attention
- Problems and Root Causes : Define the challenges, roadblocks, and supporting information of each to analyze and develop a solution
- Possible Solutions : Consider every factor involved in your corrective plan, and list down all the possible solutions to make a change for improvement
- Measure of Success : Define your success that’s measurable through key performance indicators or metrics that are applicable and beneficial to your team and overall operations
- Task Owners : Assign specific team members to every task
- Timeline: Allocate enough time to prepare for change and improvement as you go through this template

A Microsoft Word incident report template is an editable document for workplace incidents and injury accidents. It serves as a starting point for anyone to create new documents quickly, saving them time and effort in formatting the document.
The template has dedicated sections for key details: the Introduction, Objectives, Incident Information, Methodology, Findings, Conclusion, and Recommendations.

If you’re looking for an incident report template that’s still text-based but not paragraph-heavy, try an incident report in Excel ! This template is organized into four key areas:
- Incident Type Checklist
- Incident Severity Scale
- Incident Categories
- Key Contact Information
As you start to build a library of incident report forms, using Excel will get more difficult. A report template in Excel is not remote or collaboration-friendly, so versional control could get out of hand. Integrate Excel with a project management tool like ClickUp to bring all work in one place. You can access the ClickUp platform anywhere—mobile, desktop, email add-on, and Chrome Extension!
Stay a Step Ahead of Incidents With Templates by ClickUp
Your safety is every company’s top priority. So when accidents happen, you don’t want your incident report going into a drawer, never to be seen again.
Instead, follow that report, and take steps to make sure preventative measures are taken in the future!
The best way to do this? Find an incident report template that works with software designed to keep your work together, secure, and compliant—like ClickUp. 🙂

ClickUp is the only productivity platform powerful enough to streamline your safety processes, store valuable information, and keep the team aligned on all critical policies. With its own built-in and dynamic document editor, ClickUp is the ideal solution for incident reports of all kinds. Nested pages, live editing, assigned comments, and rich formatting are just a few of the features that make ClickUp Docs so valuable—but the best part? It comes at absolutely no cost.
Explore hundreds of templates for every use case, over 1,000 integrations , and rich reporting features across every pricing plan when you sign up for ClickUp , and watch your team’s productivity soar. 🛫

Receive the latest WriteClick Newsletter updates.
Thanks for subscribing to our blog!
Please enter a valid email
- Free training & 24-hour support
- Serious about security & privacy
- 99.99% uptime the last 12 months

Real Examples of Incident Reports at the Workplace with Templates

Accidents can happen, no matter how many preventative measures are in place. And, when accidents do happen, it’s vital to learn from them. To ensure your documentation is spotless, it’s always a good idea to look at some example incident reports at the workplace.
A safety incident report helps ensure nobody is subject to mistreatment because it contains information from the injured employee as well as eyewitnesses. This helps fill in missing pieces of information and figure out how the accident occurred exactly.
“The safety of the people shall be the highest law.” Marcus Tullius Cicero
So, let’s dive in!
If you’re looking for an example of an incident report at the workplace, feel free to jump to that section using the links below. Otherwise, we will first discuss what incident reports are and why they are so important.
What is a Workplace Incident Report?
A workplace incident report is a document that states all the information about any accidents, injuries, near misses, property damage or health and safety issues that happen in the workplace.
They are very important to identify the root cause of an incident along with any related hazards and to prevent it happening again in the future. As soon as an incident takes place and everybody in the workplace is safe, a work incident report should be written up.
Typically, a workplace accident report should be completed within 48 hours of the incident taking place . The layout of an accident incident report should be told like a story, in chronological order, with as many facts as the witnesses can possibly remember.
What should you include in an incident report?
There are many different types of incident reports, depending on your industry, but most will include the underlying details listed below in order to understand what happened:
- The type of incident that took place
- Where the incident happened
- The date, day and time of the incident
- Names of the people involved
- Injuries that were obtained
- Medical treatment that may have been required
- Equipment that was involved
- Events leading up to the incident that could have contributed to it taking place
- Eyewitnesses that can tell their side of the story
For example…If a chemical was involved in the incident, it should be noted if the victim was wearing appropriate PPE or not, as well as a photograph of the damage and the chemical’s label stating its components. If a workplace vehicle was involved, all information about the vehicle should be noted, and the possible reasons why it occurred if there is no clear answer. Employers should ensure vehicle safety guidelines are adhered to in order to prevent incidents in the workplace.
If this is an OSHA recordable incident (accident) and the company is exempt from OSHA recordkeeping , the employer must also fill in OSHA Form 300 . This form enables both the employer and the agency to keep a log of the injuries or illnesses that happen in the workplace. It includes crucial information such as the number of working days missed due to injury, the sort of injury that was obtained and if medical treatment was necessary.

How to Write an Incident Report
It is important to lay out an incident report clearly and concisely with all the relevant information about what happened. The clearer it is to read, the easier it will be to understand the cause of the workplace accident.
The language used for incident reporting should not be too emotional and should not purposefully put the blame on someone. Here is an incident report example template:
This workplace incident report template includes the basic guidelines and best practices of what to include to make sure the report includes all the details it should. Once a report is written, it should be kept on record in the workplace.
Incident Report Examples
Depending on the type of workplace incident, the writer will need to include various pieces of information. If you are not sure how to write an incident statement, here are example incident reports for the workplace covering various scenarios.
Injury Incident Report Example
“At 11.20am on Tuesday 7 th July 2020, a worker, Timothy Johnson, tripped over an electrical wire on the Blue & Green construction site, located on Main Street, Riverside. He was carrying a hammer at the time.
It is believed the wire should not have been stretched across the ground without safety tape securing it to the ground and drawing attention to it. Timothy fell to the ground and dropped the hammer but did not injure himself with it. He twisted his ankle, which immediately began to swell and scrapped the side of his leg in a minor way. A co-worker came to assist Timothy to his feet and helped him walk to a nearby bench. Timothy could not put his weight on his left foot, so he was taken to a nearby hospital. Once at the hospital, doctors confirmed that Timothy had sprained his ankle and would have to keep the foot elevated and use crutches for the next two weeks. He would not be able to work during this time.
The foreman for the construction site has assessed the wires on the ground and concluded that brightly colored tape should secure the wires to the ground to draw attention to them and to ensure there are no bumps in the wire that are easy to trip over so that this does not happen again”.
Forklift Accident Report Sample
“On Friday 5 th July 2020, at 3.35pm, a forklift driver, Max White, was driving the forklift he usually drives in the Sunny Side Warehouse, ABC Street, when the front right tire got caught on a piece of wood on the ground, causing the forklift to overturn with Max inside it.
Luckily a co-worker was nearby to help Max climb out of the right side of the forklift. Max was shaken up and reported that his left shoulder and left side of his neck were hurting him from the impact. Max decided he did not need to go to the hospital as he felt like he would only obtain bruises from his injuries and that they were not severe enough to need medical attention. His manager sent him home for the rest of the day to ensure he did not strain himself further.
The wood that caused the forklift to overturn had not been stacked properly and has now been moved to a secure location in the warehouse to make sure it does not cause any more issues for forklift drivers”.
Fall Incident Report Sample
“In Fairview Boutique on Friday March 6 th , 2020, Samantha Wright was stacking shelves while standing on a ladder in order to reach the top shelf of handbags at 4.10pm. As she was stretching to place a bag on the shelf, the ladder collapsed from under her and she fell to the ground. Her co-worker heard the loud noise and immediately helped her. Samantha was in a lot of pain and could not get to her feet as she felt lightheaded. An ambulance was phoned, and she was brought to hospital. Samantha obtained a broken right arm, bruised thigh and hip, and a bump to the head that left no major head injury. She was recommended three weeks off work at the minimum by doctors. The fall was concluded to be of nobody else’s fault but was put down to Samantha accidently overreaching instead of moving the ladder to where she needed to see”.
Hand Injury Incident Report Sample
“On April 21 st , 2020, at Willow Maintenance, Yellow Abbey Grove, Kyle Jenkins was about to use a miter saw to cut some timber, but when he started to use the saw, it jolted, causing the saw to come down suddenly on his hand.
Kyle’s left thumb was cut deeply by the saw and he lost a lot of blood. Co-workers came to his aid, turned the saw off and helped him stop the bleeding with tissues. He was then brought to the hospital where he received eight stitches and was told to not use the hand for rigorous work for 4 weeks. The head of Willow Maintenance inspected the saw to check for any issues and see why it came down and cut Kyle’s hand. It appeared that whoever was the last person to use the machine did not put the safety latch back on the saw once they had finished using it.
If this safety latch was on the saw when Kyle used it, it would not have cut his hand, but rather, automatically shut off once it jolted. The manager decided to take a day to retrain his staff to ensure they adhere to the health and safety guidelines of the company”.
Exposure Incident Report Sample
“In Woodbell factory, Springville, on Tuesday May 26 th , 2020, Annie Bedley was packaging household cleaning products when a bottle tipped over onto her wrist.
She got up from her seat to wash off the chemical in the washroom. She then went to her supervisor to show her what had happened. Annie’s wrist was red and itchy but was not burning as she had washed off the remnants of the chemical immediately. Annie’s supervisor brought her to the office to sit with a cold compress on her hand and applied a layer of ointment to treat the burn. Annie did not feel like she would need further medical assistance and agreed with her supervisor that she would need two to three days off work to ensure the burn did not get irritated.
Annie was wearing appropriate PPE at the time of the incident and no faults were found on the conveyor belt at the packing bay. The incident has been noted as an accident with nobody to blame. Photographic evidence of the burn has been included in this file”.
First Aid Incident Report Sample
“On Friday November 15 h 2019, Arthur Stokes was walking along the corridor between building four and five of Graygrock Inc. when he noticed that there was something sharp sticking through the bottom of his right shoe.
He stopped to see what it was and found a nail stuck in his shoe. He took his shoe off and lucking was able to pull the nail out as it hadn’t pierced through to his foot and only minorly scraped it. He saw the stairwell was getting new handrails fitted and presumed the nail came from that. He saw two other nails further along the corridor and decided to pick them up to make sure nobody else stood on them. He reported to his manager’s office where he presented the nails and explained the situation. His foot had a small cut, so Arthur’s manager gave him an anti-septic wipe and a band-aid to help him.
Arthur returned to work while his manager talked to the construction workers about keeping their workspace neat and to prevent any further accidents like this from happening”.

Incident Report Form Templates
The layout of an incident report forms can vary depending on where the incident took place and the type of injuries. Here are some examples of incident reports at the workplace that you can use.

Incident Report Form for General Staff (Word/PDF)
This general staff accident report form template can be used in a variety of workplaces. It includes all the necessities to describe a workplace incident to ensure it is recorded correctly. This general form is ideal for any business type.

Incident Report Form for a Construction Site
This example incident report for the workplace is unique to others as it includes a field for the construction project name and the project manager’s details. This makes it easy to understand where in the construction site the accident occurred and how severe it was.
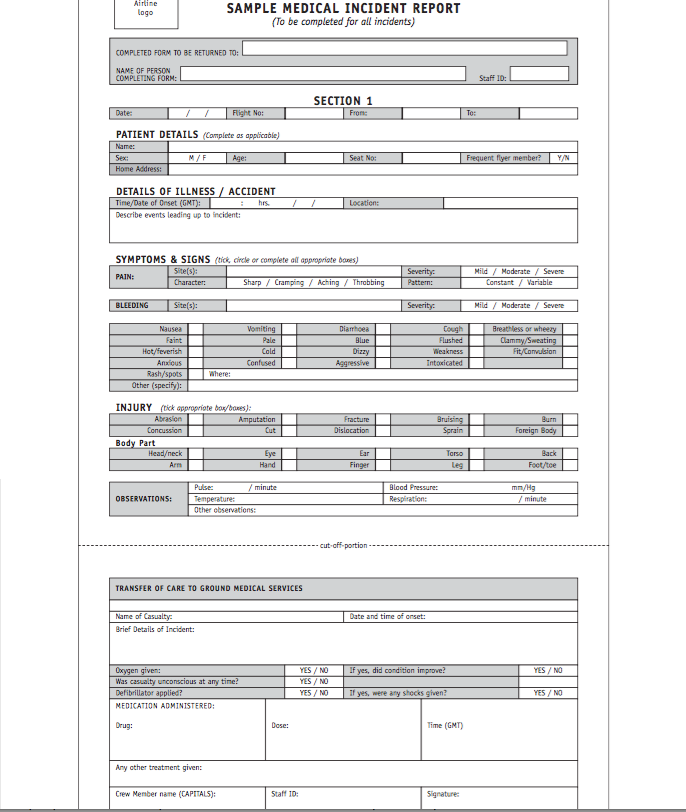
Incident Report for a Hospital/ Medical Clinic (Word/PDF)
The hospital incident report template is much more detailed than others as it must include accurate information about the staff member or patient’s injuries, where in the hospital it happened and what medical treatment they required.
As you write your workplace incident reports, remember it is not to place blame on one person, but rather record a series of events that have taken place. Sometimes these are pure accidents due to bad luck and, sometimes, there is human error or a technical fault involved. By the way, this is the basis of the Just Culture Algorithm™ which is definitely worth exploring if you’re looking to improve the safety culture at your workplace .
These examples of incident reports at the workplace are only the tip of the iceberg when it comes to the variety of workplace accidents that can occur. In any case, it’s crucial to record any incidents that arise because this helps create a safer work environment.
References & Further Reading
- OSHA’s Guide for Employers carrying out Incident Investigation
- OSHA’s Injury & Illness prevention Program
- Workplace Injury Information
- Eyewitness Statement Form : Should be included for any eyewitnesses to the incident to aid the investigation.
- Injury Investigation Questions : Should be asked when an employee has been injured at the workplace to understand exactly what happened.
- Incident Investigation Flowchart Procedure: A step by step example of the procedures involved in carrying out a workplace incident investigation.
Related Posts
The 18 near miss reporting examples you need to know.
Type above and press Enter to search. Press Esc to cancel.
- Contact sales
Start free trial
Get your free
Incident Response Plan Template
Use this free Incident Response Plan Template for Word to manage your projects better.

Cybersecurity should be on the top of mind for anyone managing a website, working with technology or any digital device. While technology can create benefits for the organization, they’re also an entry for spammers and worse to infiltrate and destabilize. To prepare for data breaches, download this free incident response plan template for Word.
What Is an Incident Response Plan?
An incident response plan template is a structured approach for identifying, responding to and managing cybersecurity incidents or data breaches. It emphasizes a proactive approach, ensuring that all team members understand their roles and responsibilities in the event of an incident.
The incident response plan is tailored to the specific needs and risks of the organization, taking into account the types of data and systems in use. It encourages regular training and simulations to keep the response team prepared for real incidents.
There are also communication strategies involved to keep stakeholders, including employees, customers and regulators informed during and after an incident. This helps to build trust and transparency.

Why Use an Incident Response Plan Template?
There are many reasons why an incident response plan template should be used. The fact that it’s a template alone means that it standardizes the response so everyone involved is familiar with the format. The template makes it easy to get started without having to build the IT project plan each time from scratch.
Minimize Damages
Beyond the benefits of a template, this specific incident response plan template can help an organization minimize damage by quickly and effectively responding to incidents. This reduces the potential impact on systems, data and operations. It also improves recovery time by providing clear procedures and roles, which allow the organization to resume normal operations sooner.
Improves Communication
Don’t forget, the template acts as a communication tool by establishing protocols for internal and external communication. This makes sure that all stakeholders are informed and coordinated during a crisis. In terms of the bottom line, an incident response plan reduces costs. It mitigates the effects of incidents and streamlines response efforts to lower the financial impact associated with breaches and downtime.
Kickstarts a Process
By instituting regular reviews and updates to the incident response plan template based on the lessons learned, users are promoting continuous improvement. This strengthens overall security and preparedness. It also reassures customers, partners and stakeholders that the organization is prepared to respond to threats effectively.
The problem with an incident response plan template is that it’s not as effective as project management software. The former is a static document, the latter a dynamic suite of powerful features.
ProjectManager is award-winning project and portfolio management software with risk management tools that automatically update and capture real-time data for more efficient incident response planning. Our risk management task cards allow users to identify risks, indicate their impact, the likelihood of occurrence and view a risk matrix to help prioritize response. There’s also space to describe that response, attach relevant files and comment in real-time so teams can collaborate when an incident happens to mitigate it faster. Get started with ProjectManager today for free.

Who Should Use This Incident Response Plan Template?
An incident response plan template is a versatile tool for cybersecurity. There are a number of stakeholders within an organization that will find it valuable to use. They are as follows.
- IT security teams
- Incident response teams
- HR department
- Legal and compliance teams
- Public relations teams
- Risk management teams
When Should You Use This Incident Response Plan Template?
There are any number of incidents in which this response plan would be valuable. Some of the more obvious ones are listed below.
- Cybersecurity incident
- Data breaches
- System failures
- Suspicious activity
- Regulatory compliance
- Testing and drills
- After a near-miss
How to Use This Incident Response Plan Template
Download the free incident response plan template for Word and open a fully customizable document. This can be adjusted as one sees fit. For example, it’s easy to add the company logo. Everything else has been outlined by us.
Incident Response Team
The first section lists the people who are responsible for identifying and mitigating the incident. This chart has multiple rows to capture everyone’s name, a description of their role and responsibilities .
Incident Detection and Analysis Procedures
In this field, describe the method, tools and procedures that will be used to detect and analyze IT incidents .
Incident Classification and Prioritization
This is where the incident or incidents are cataloged. The section is broken down into four columns. The first is to describe the incident. Next, the likelihood of it occurring is noted, such as high probability to low. After that, the potential impact of the incident will be determined. This all leads to the final column, which prioritizes the response to the incident if it in fact occurs.

Containment Strategies
When one of the incidents identified above does occur, then this section will describe the response. Not only is the strategy deployed to mitigate the IT incident but the members of the team who will be assigned to carry it out. This is outlined on a chart that describes the incident, the containment strategy, who’s assigned to execute that strategy and the priority level.

Recovery Plan
This step is taken once the incident has been detected, contained and eradicated. Now, the IT management team needs to make a recovery plan , which is a set of action steps that will be followed to safely bring the system affected back online while minimizing downtime and data loss.
Post-Incident Analysis: Lessons Learned
After all this has been done, the team should evaluate the performance of the incident response and identify areas of improvement. They can then update the plan as needed and apply these fixes to future incident response plans so they work even better.
Related Incident Response Plan Templates
The incident response plan template can be further helped with the addition of these templates, which are just a few of the over 100 free project management templates for Excel and Word that can be downloaded from our site.
Issue Tracking Template
When on the incident classification and prioritization step, this free issue tracking template can help. It lists potential incidents, their impact and prioritizes them. If the incident occurs, that date can be recorded as well as when it’s closed and who is responsible for mitigating it.
Action Plan Template
For the recovery plan, use this free action plan template for Excel to map out how issues will be repaired in a timely manner. The action plan is divided into project phases, each of which list tasks, start and end dates for that work, costs and a lot more.
Lessons Learned Template
Use this free lessons learned template for Excel during the post-incident analysis period of the incident response plan. It lists what happened, the impact, how it should change in future projects and action items to make it so.
How ProjectManager Helps With Incident Response Planning
Templates are not the more advanced tool for dealing with IT incidents. For those not ready to upgrade to project management software they’re better than nothing. However, these static documents that require manually data inputting and are a poor platform for collaboration can turn an incident into something worse. Incidents must be identified quickly and responded to even faster so recovery isn’t as pronounced. ProjectManager is award-winning project and portfolio management software that has the risk management tools IT teams need to stay on top of issues and mitigate them.
Use Gantt Charts to Plan Containment
Better than an action plan template, our robust Gantt charts lists tasks, sets milestones and can link all four types of task dependencies to avoid delays. It’s easy to filter for the critical path to identify essential tasks in the mitigation strategy. Then set a baseline to track progress in real time. IT teams can use one of our multiple project views to execute their tasks, such as the visual workflow of kanban boards, powerful to-do list views or the overview of the calendar view, which can also keep stakeholders updated on progress.

Track Progress, Cost and More in Real Time
Once the containment plan is executed, managers can monitor the progress from a high level with real-time project and portfolio dashboards . They automatically collect live data and display it on easy-to-read graphs and charts that show time, cost, workload and more. Customizable reports go deeper into the data for managers and their teams, but can also be filtered for a more general view to keep stakeholders informed. Secure timesheets offer transparency into labor costs to keep the work on budget.

Related IT Content
IT departments are responsible for more than managing and mitigating incidents. Below are some of the more recent pieces we’ve published on IT project management, IT incident management and a roundup of free IT project management templates.
- IT Project Management: The Ultimate Guide
- IT Incident Management: How to Manage IT Incidents
- 17 Free IT Project Management Templates
- IT Risk Management Process, Frameworks & Templates
- IT Governance: Definitions, Frameworks and Planning
ProjectManager is cloud-based project and portfolio management software that connects teams whether they’re in the office or out in the field. They can share files, comment at the task level and stay up to date with email and in-app notifications. Join teams at Avis, Nestle and Siemens who use our software to deliver successful projects. Get started with ProjectManager today for free.
Start your free 30-day trial
Deliver faster, collaborate better, innovate more effectively — without the high prices and months-long implementation and extensive training required by other products.
- Agriculture
- Construction
- Manufacturing
- View all industries
- Case Studies
Incident Report Samples to Help You Describe Accidents
Your company’s incident report form should make it easy to record the details of a workplace accident. Even fill-in-the-blank forms require a long-form description of the incident. This portion of the report can be the most difficult part to write.
In this article, we provide completed incident report samples to help you hone your documentation skills.
What Does an Incident Report Need to Include?
An incident report is a formal recording of the facts related to a workplace accident, injury, or near miss . Its primary purpose is to uncover the circumstances and conditions that led to the event in order to prevent future incidents.
Every incident report you file should contain a minimum of the following:
- Type of incident (injury, near miss, property damage, or theft)
- Date of incident
- Time of incident
- Name of affected individual
- A narrative description of the incident, including the sequence of events and results of the incident
- Injuries, if any
- Treatments required, if any
- Witness name(s)
- Witness statements
- Other workers involved
- Video and/or 360-degree photographs of the scene
Include quantifiable measurements where possible. For example, the ladder capacity is 250 lbs and the victim was hoisting 300 lbs.
Finally, where more than one person is injured in an incident, create a unique report for each affected employee . While it’s fine to duplicate general details between reports of this nature, you’ll need to include details specific to that person, such as the event from their point of view or medical records.
When Does an Incident Report Need to Be Completed?
Create an incident report as soon as your employees are safe , which includes seeking medical attention and implementing an immediate corrective action to prevent further danger or damage.
By recording details immediately, you improve the accuracy of your report and the effects of your corrective actions. While it may take a few days to complete your report, it should take you only hours (or less) to start it.

Depending on your company policies and oversight from relevant regulatory bodies, you may be legally bound to complete an incident report within a given amount of time. If the incident resulted in a recordable injury, you must complete OSHA Form 301 within seven days. In addition, you may need to send your report to the organization providing oversight, US Federal or State OSHA , for example, within a given period of time.
Review federal OSHA incident reporting and recordkeeping requirements or visit your state OSHA website for details. Remember that you must also report a fatality, hospitalization, or amputation directly to OSHA.
Safety Management Tip : Safesite Premium users enjoy streamlined OSHA incident recording with Safesite’s OSHA300 log integration feature .
Incident Reporting Mistakes to Avoid
Incident reports are more than a mandatory form to complete: they’re a vital part of your recordkeeping practices both for compliance and safety in general. Their importance means you want to get as much relevant information as you can as quickly as possible. But sometimes, safety teams can get in their own way and miss out on important details by making common mistakes.
Blame-casting and just getting it done are two common incident reporting mistakes you should avoid.
It is easy to go on a witch hunt when accidents happen. However, incident reports aren’t created for the purpose of finding out who’s to blame. While staff should be held responsible (as stipulated by company policy) when they knowingly endanger themselves others, an incident report should focus on improving workplace safety.
If you make it clear you’ll abide by company policy but are not out to cast blame, you increase the likelihood that employees will participate in your incident investigation and provide honest witness statements. These factors create a stronger incident report.
In addition, if you rush through the report to “just get it done,” you may miss out on important details or lack clarity in wording. Irresponsible reporting can lead your team into even more danger, while detailed, clear reporting can lead to improved work conditions and better training.
Three Incident Report Samples
Below are some sample incident report formats for three common types of workplace accidents. Use them as guides to effectively describe events.
Injury and Lost Time Incident Report Sample
If an injury requiring medical treatment, lost time/altered responsibilities happens in your workplace, it’s important to document it ASAP while the details are still fresh in memory.
Here are some of the vital elements to include in your description of the incident:
- Location (Address)
- Date/time of incident
- Name of supervisor
- Description of the incident, including specific job site location, the sequence of events, and the results of the event
- Whether or not proper PPE was being used
- The root cause(s) of the incident
- Associated hazards raised and resolved following the event
- The affected individual’s version of the events
- Actions taken by concerned individuals after the incident
- Description of injuries
- How the decision was made to call (or not to call) emergency services
- Treatment required
- Photographs of the scene
Though the details above seem excessive, mentioning them in the incident report paints a more accurate picture. It’s important to include the above information in as detailed and concise a manner as possible. Holes in your report could lead to inferences and missed opportunities to create a safer workplace.

To write an incident report, use a narrative format. In other words, simply tell the story. Here’s an incident report sample description of a slip or fall resulting in a fracture, written in narrative form:
“On Friday afternoon, February 3, 2019, at 2 p.m. in ABC Shipping Co. located in 13th Avenue, Applewood, one of the warehouse workers (John Keegan) slipped and fell while carrying heavy (85 lbs) inventory. The root cause is believed to be the unavailability of a hand truck or pallet jack. Instead of waiting, John attempted carrying the load himself. A second possible cause is the condition of John’s PPE, specifically his boots, which are very worn in certain places.
When John fell, his colleagues rushed to his assistance. Suspecting a fracture, the supervisor on the floor (Kathy Pickens) decided to call 911. John said he felt a bit dizzy when he lost his balance and that he just ‘tripped over his feet.’ He tried to minimize damage to the load itself while falling, which may have led to a more awkward fall.
Two of his co-workers said that they noticed he was struggling a bit before the fall, but were busy with their own tasks and felt it would be rude to ‘call him out.’ See the attached witness statements for more info.
John was taken to a nearby hospital and a fracture to his wrist was confirmed. John will be out of work for a number of weeks.
The supervisor is currently working with the safety officer (Chris Darnell) to assess the condition of the floor, the number and condition of hand trucks and pallet jacks on the floor, as well as the condition of company-provided boots over two years old.”
As you can see, including the full story, complete with small details and witness statements will help you investigate and recall the incident with greater clarity.
After documenting the incident, you may have legal reporting requirements. Report and store the files according to recordkeeping requirements from regulatory bodies. It’s generally best practice to preserve the files for the duration of employment.
Exposure Incident Report Example
When exposure to dangerous chemicals or pathogens occurs, it’s important to document the event carefully in an incident report.
Including the following details will make your exposure incident report more effective:
- Name of affected individual
- Name of Supervisor
- Description of the incident, including specific job site location, sequence of events, and results of the event
- Name of the chemical/pathogen/carcinogen, amount, concentration, and description of hazard labels/safety data sheets (SDS)
- Exposure monitoring data, if available
- Whether or not a contaminated sharp was involved
- Description of injuries, including body part(s) exposed, length of exposure, and size of area exposed
- Signs and symptoms displayed
- Photographs of the scene and hazard labels involved

Here’s an incident report sample description for overexposure via inhalation:
“Josh Lee, a freight handler in XYZ Shipping Lines, was exposed to carbon monoxide fumes on December 2, 2017, Tuesday, from (estimated) 7:30 AM to 11:30 AM. He was at the unloading bay B, helping unload some freight from various containers with the help of two forklift operators: Kit Stevens and Donald Summers, neither of which complained of symptoms.
During unloading, Lee suddenly experienced lightheadedness and nausea. He informed his supervisor (Donna Martin) that he thought he was ill.
Martin noticed his symptoms were consistent with CO exposure, so she walked over to the area and felt the air quality seemed off. She ran a sensor (Portable Direct Reading Monitor) and discovered that CO levels were on the high end but within the acceptable limit: 30 PPM.
Stevens and Summers were ordered to turn off powered vehicles and sit in fresh air for an hour while the ventilation system could be examined (see attached report).
Lee was driven to the hospital by Martin to receive treatment. On the way, he complained of blurred vision briefly but said that it had cleared up upon walking into the ER. A full report will be attached once received.
Lee’s colleagues, Stevens and Summers, didn’t notice anything out of the norm with the air quality, but Summers acknowledged that at 11:00 AM, his vehicle had been left running near the open end of a container for thirty minutes while Lee was adjusting two improperly arranged pallets just inside. There is no air quality data from that time.”
Be sure to attach medical reports and lost-time from work, if any, to your initial report. Keep the report on hand for the duration of the employee’s tenure with the company, at a minimum.
First Aid Incident Report Sample
Some workplace mishaps result in an injury that requires on-site or walk-in medical first aid treatment. Often, workers can return and finish their shift. Recording an incident report is still vitally important, even where it’s not expressly required by regulatory bodies.

Here is an incident report sample description for incidents resulting in the need for first aid.
“ On May 12, 2019, at around 9:34 AM. at King Street job site, Michael Williams was hit by an air nail gun that had been dropped by Carl Simone near the top of a staircase and gained momentum as it tumbled down.
Williams, who was nailing drywall at the bottom of the staircase and wearing noise protective headphones, eye protection, and a short-sleeved shirt, was hit in the arm, causing a bruise and abrasion. He was treated with antiseptic, antibiotic ointment, a bandage, and an ice pack on site. Williams returned to work within a half hour.
Simone had shouted a warning after he dropped the gun, but Williams said he did not hear it. Simone said that he simply lost his grip, but Williams said he felt that the tool may have been ‘swung’ before dropping. There were no other witnesses to report on the circumstances of the accident.
Simone was wearing gloves when he dropped the nail gun. There are no outstanding hazards related to this incident and all workers will be reminded about glove selection and tool handling at the next safety meeting.”
While you should always document injuries requiring first aid internally, you typically don’t need to add them to your Form 300A or other regulatory reporting. In fact, doing so can needlessly elevate your incident rate.
An Incident Report Template to Improve Your System
Your incident reporting system should allow your employees to easily document all of the information listed in the incident report samples above. If your incident forms are easy to fill out in the field, you’re more likely to capture accurate, timely information.
With Safesite, you can complete an incident report in six easy steps:
- Tap Log Incident
- Select your inicent report type (injury, near miss, property damage, theft, or equipment failure) and location, date, and time
- Input your incident description and an incident photo
- Tag the person involved and witnesses from your team
- Complete root cause analysis
- Log your incident

Safesite’s incident report form can be filled out on-site via iOS or Android app. It includes places to record the details of the event, images of the scene, and witness statements. It also allows you to raise associated hazards and identify a root cause.
An incident report can also be completed using paper, but many companies now look to secure software to not only document and store incidents but also to trend problem areas and reveal safety gaps.
Not ready to go mobile yet? Here’s a paper template you can edit and use in the meantime:

Raising and Resolving Hazards
Many incidents and near misses will involve hazards that could cause immediate or future harm to your employees if not resolved. From tagging and removing damaged equipment from service to safely dismantling corrupted structures, your incident reporting process is not truly complete until you resolve the danger.
To keep things straightforward, include hazard descriptions and actions on your incident reports. With Safesite, you can create hazards from within an incident report by tapping Add Root Cause Hazard. Then, you’ll be able to alert your team of the hazard in real-time and assign it to someone for resolution. And you can do it without deviating from your incident report.

Tip: Want to streamline hazard management without missing a beat? Check out our guide to faster hazard recognition and resolution .
Go Forth and Report
When writing incident reports, be objective about the details. Your main goal is improving workplace safety, not pointing fingers at who is responsible. The incident report samples provided show that by staying true to the facts, you encourage employee participation in your investigations.
Digital reporting automates part of the process, saving you time and reducing human error. Improve your incident reporting process by using a digital reporting tool, like Safesite , that integrates alerts and hazard resolution in a single place.
- First name *
- Last name *
By Team Safesite
We're a group of safety and tech professionals united in our desire to make every workplace safer. We keep a pulse on the latest regulations, standards, and industry trends in safety and write about them here on our blog.
This article covers:
Related blog posts, why employee engagement is the key to unlocking safety program performance, everything you need to know before changing your safety software, safesite’s step-by-step guide to safety program digitization.
Incident Report Templates
Venngage's incident report templates streamline the documentation process, providing a structured framework for recording critical events and ensuring accuracy in reporting. Customize professional designs for efficient incident reporting and analysis.

Other report templates
- Human resources
- Executive summary
- Survey results
- Project status
- Construction
Popular template categories
- Infographics
- Presentations
- White papers
- Letterheads
- Newsletters
- Business cards
- Certificates
- Invitations
- Social media
- Table of contents
- Magazine covers
- Price lists
- Album covers
- Book covers
- See All Templates
Incident Report Examples & Templates
Knowing how to effectively file incident reports is a critical component for companies that want to cultivate their culture of safety at work. Incident reports are designed to document the important details surrounding an accident, incident, or near miss that happens in the workplace.
These reports are incredibly useful for informing companies on the real gaps that exist in their safety protocols, ultimately allowing them to address these issues by implementing new policies and protocols to prevent future incidents from occurring.
In this article, we cover three of the most common incident report types and the corresponding report templates that you can use. Continue reading for examples and templates to use when these types of incidents happen at your workplace:
- Basic Incident Report
- Field Incident Report
- Construction Accident Investigation Report
- Basic incident report template & sample
If you need a basic template to get started, make sure to check out our basic incident report template that’s free to get started with using the GoCanvas app store. Our template includes the most common information to include in a basic incident report and it can be fully customized to meet your company’s specific requirements.
What are basic incident reports used for?
Basic incident reports work for a variety of types of incidents, giving you a flexible template that can be used for different types of accidents, near misses, or injuries. A basic incident report template should include all the essential details that you and the investigative teams will need to fill out following the incident.
How often basic incidents occur
Wondering how often basic incidents occur? If you look at the most recent findings from the Bureau of Labor Statistics, it shows that the rate of recordable incidents in the private industry was at 2.8 percent among full-time workers. The data shows that nearly 900,000 incidents resulted in lost time when looking across all of the reported incidents in a given year.
Key info for basic incident reports
A basic incident report needs to include all the details the investigative team will need to evaluate during their review, including:
- Location, date, and time of the incident
- Witnesses and their contact information
- Witness testimonies
- Those involved in the incident
- Actions that were taken post-incident
- Injuries incurred
- Medical treatment administered
Field incident report template & sample
When an incident happens in the field a report must be filled out and sent to the proper authorities. Get started for free on the GoCanvas app store, using our field incident report template that allows your field teams to use a mobile device or tablet when submitting their reports.
What are field incident reports used for?
You will need to use a field incident report for any work-related injuries that occur offsite or outside of company property. Field incident claims are typically more complicated than claims filed for an on-site incident. With that in mind, you should make sure to be thorough when collecting the details of a field incident to ensure that claims are efficiently processed.
Key info for field incident reports
In addition to all the information included on a basic incident report, field incident reports should also include the location of the accident and the address of the workplace.
- Construction accident investigation report template & sample
The perfect tool for any construction company is available through the GoCanvas app store using our construction accident investigation template. Use this resource so that your construction company is prepared when a workplace accident occurs.
What are construction accident investigation reports used for?
You know that the construction industry presents a wide range of hazards and dangers. Construction accident investigation reports are crucial to identifying weak points in safety protocols and they can actually help your business establish better safety practices. These reports can help your company and they can also help inform the entire construction industry on how to better minimize injuries on job sites.
How often construction accidents occur
If you look at data provided by OSHA, you will see that construction accidents are the most common type of reportable incident and about 20 percent of fatalities in private industry are in construction. The most commonly violated OSHA standard is fall protection, which falls under the construction sector.
Key info for construction accident reports
In addition to all the information required on a basic incident report form, a construction accident investigation report should also include the name of the contractor, the name of site foreman, and any violations that were issued.
- Additional templates available for all your use cases
Documenting incidents and injuries is crucial for promoting a culture of safety in the workplace. With incident report templates on hand, you’ll be able to document any accidents when they happen, and your team can work to improve its protocols for a safer workplace.
If you’re looking for additional incident report templates that we didn’t cover in this article, be sure to check out more examples of incident reports in our app store. We have hundreds of pre-built forms to help you get started and our product has a variety of features that will fit all your business needs.
- Field incident report t emplate & sample
Stay in Touch!
About gocanvas.
GoCanvas® is on a mission to simplify inspections and maximize compliance. Our intuitive platform takes care of the administrative tasks, freeing our customers to focus on what truly matters – safeguarding their people, protecting their equipment, and delivering exceptional quality to their customers.
Since 2008, thousands of companies have chosen GoCanvas as their go-to partner for seamless field operations.
Check out even more resources
The ultimate guide to quality control inspections.
Managing a construction project is a complex and stressful process. Among other things, you have to coordinate project team members, materials, and equipment and ensure that contractors are not afflicted by the potential risks and hazards present at the construction site. That said, quality means different things to different people which is why you should…
Constructions Digital Transformation
Your competition is finding faster ways to capture data and get critical insights from the field into their existing systems. In short, they’re not going bigger, they’re getting smarter. In this 15-minute broadcast on the construction industry’s digital transformation, find out why the trend is to modernize workflows – and how you can stay ahead of the curve…
See how VIP Lighting optimized efficiency with GoCanvas
VIP Lighting is a retail lighting and electrical maintenance business that services over 10,000 retail locations all over Australia and New Zealand. Before GoCanvas, VIP Lighting had two separate systems that were impossible to integrate, leading to inefficiencies. GoCanvas made it easy to integrate their systems into single, centralized platform…
Connect with an Expert Today.
We’ll help you put together the right solution for your needs..
This incident report template is free to use, completely customisable, and makes the job of reporting, recording and mitigating incident easy and reliable.
Site incidents are inevitable, but we can always do a better job of recording and learning from incidents to better help employees and mitigate the occurrence of future incidents.
The best way to systematically record and organise any and all site incidents is to use an incident report. Incident reports cover the full spectrum of incidents - from a near miss to a first aid or medical treatment injury.
The incident report serves as the forum for reporting the incident properly, and then notifying other stakeholders or parties with a copy if that report - which may be further investigated or used as a tool for improving safety now or in the future.
This complete incident report template comes pre-built with all the fields you need to record and manage incidents properly and safely:
- Automated form ID #
- Supervisor/manager reporting incident
- Date and time of incident
- Incident classification
- Name of injured person, contact number and company involved
- Description of what happened with supporting photo/s and sketch
- Description of immediate actions taken and the relevant causes
- Corrective action table
- Additional checklist questions
- Digital signature of investigation officer
Free Incident Report template (easily customisable)
Incident report templates // incident templates // safety templates.

So how does this digital incident report template work?
See how this smart and easy-to-use incident report template works for yourself. click to open a report, toggle between display views and even edit the actual template (form questions)..
Try it for yourself →
Use this better incident report template for free.
This incident report template is powered by dashpivot project management software..
- Easily edit or add form fields with simple drag-and-drop functionality and customise the report to your liking.
- Access and use your incident report from anywhere - on laptop, computer, mobile or tablet.
- Take and add supporting attachments to your report in the office or on site.
- Format your completed incident reports into list view or register view at the click of a button.
- Instantly download, print or send your finished reports as custom branded excel or PDF documents.
Dashpivot is user friendly safety management software trusted by the industries on all kinds of jobs and projects.
Other popular Safety templates you can get started with for free.

Incident Notification Form template
Document incidents and near misses properly, and more easily.
See the template →

Excavation Permit template
Complete those incredibly important excavation permits safely.

Utility Service Locating template
Ensure better excavation & safety outcomes by doing the right investigative work.
People in 70+ countries use this safety management system to improve how they document and track safety.

Start easily streamlining your processes with Sitemate today
- Training Portal
- GET YOUR CAUSE MAPPING® TEMPLATE

- About Cause Mapping®
- What is Root Cause Analysis?
- Cause Mapping® Method
- Cause Mapping® FAQs
- Why ThinkReliability?
- Online Workshops
- Online Short Courses
- On-Demand Training Catalog
- On-Demand Training Subscription
- Company Case Study
- Upcoming Webinars
- Webinar Archives
- Public Workshops
- Private Workshops
- Cause Mapping Certified Facilitator Program
- Our Services
- Facilitation, Consulting, and Coaching
- Root Cause Analysis Program Development
- Work Process Reliability™
- Cause Mapping® Template
- Root Cause Analysis Examples
- Video Library
- Articles and Downloads
- About ThinkReliability
- Client List
- Testimonials
- There are no suggestions because the search field is empty.
Join us for the next Cause Mapping Root Cause Analysis Public Workshop in HOUSTON, TX on December 10-12, 2024.
Root Cause Analysis Examples - - - - - - - - - - - - - -
Cause mapping examples and case studies - - - - - - - - - -.
The following root cause analysis example incidents demonstrate how Cause Mapping can be used to document problems and identify solutions in various industries. Select an industry on the left to view its case studies on the right. Each example has a downloadable PDF to accompany the write-up.
Attempted Bombing of Flight 253– Explosives allowed on a flight to Detroit
Wrong plane (unaccompanied minor flown to wrong city) – don’t stop at “procedure not followed”, us airways flight 1549 (miracle on the hudson) – a root cause “success” analysis, lexington plane crash – attempted take-off on the wrong runway, concorde accident – a failure causes a plane to crash, twa flight 800– mid-air breakup kills 230, de havilland comet accidents – problems with the “most exhaustively tested airplane in history”, hindenburg explosion– an example of debated causes, financial mess - the 'housing bubble' burst and more, hurricane katrina - 80% of new orleans flooded, 1100+ deaths, yarnell hill fire - 19 firefighter fatalities, deepwater horizon oil spill - oil spill lasts for months as solution after solution fails, cats & rabbits on macquarie island - an example of unintended consequences, fire - decoding the fire triangle and fire tetrahedron, buffalo creek flood of 1972 - dam failure causes massive damage and 125 deaths, pet food contamination - unsafe substitution of products.
These statistics are startling to some and unsurprising to others. So you can imagine the uproar, panic, fear and anger it might cause when pets are endangered. And you can imagine how pet owners must respond when their own pets are endangered…
Guinea Worm Disease - Working to eradicate a painful parasite
Hot coffee (the spilled mcdonald's coffee) - debate to the solutions, not the cause, smoking - why do people start why don't they quit, fukushima daiichi- natural disasters damage nuclear power plant, deepwater horizon oil spill - oil spill lasts for months as solution after solution fails, dust explosions - a root cause analysis primer, explosion at point comfort formosa facility - vehicle accident results in large propylene release, davis besse reactor corrosion - potential breach of containment, three mile island - partial meltdown of the core, buncfield storage depot explosion - 43 injured after tank overfilled, triangle shirtwaist fire - 46 workers killed in fire, wrong plane (unaccompanied minor flown to wrong city) - don't stop at 'procedures not followed', hot coffee the spilled mcdonald's coffee - debate the solutions, not the cause, loss of the kursk - a submarine and all crew members are lost, valdez oil spill - oil tanker strikes reef, loss of the titanic - there's more to it than the iceberg.
1) Define the problem
2) Analyze the causes
3) Select the best solutions…
Hubble Focusing Issues - Focus on solutions, not 'the' problem
Loss of columbia on re-entry - foam strike leads to loss of crew, loss of the mars orbiter - english and metric units confused, challenger explosion - o-ring leaks in cold weather, fire aboard apollo 1 - fire during launch pad testing kills 3 astronauts, i-35 bridge collapse - undersized gusset fails after 40 years, hyatt regency walkway collapse - inadequate structural design, cook county administration building fire - botched evacuation kills 6, new london school explosion - hundreds killed when natural gas explosion levels school, 1942 fire at the cocoanut grove nightclub - nightclub fire kills 492, tacoma narrows bridge (galloping gertie) - the collapse started in the design phase.
- The Root - RCA blog
- Root Cause Analysis blog archive
- Patient Safety blog archive
- Learner Dashboard
© 2024 ThinkReliability. All Rights Reserved.
How to write a case study — examples, templates and tools

It’s a marketer’s job to communicate the effectiveness of a product or service to potential and current customers to convince them to buy and keep business moving. One of the best methods for doing this is to share success stories that are relatable to prospects and customers based on their pain points, experiences and overall needs.
That’s where case studies come in. Case studies are an essential part of a content marketing plan. These in-depth stories of customer experiences are some of the most effective at demonstrating the value of a product or service. Yet many marketers don’t use them, whether because of their regimented formats or the process of customer involvement and approval.
A case study is a powerful tool for showcasing your hard work and the success your customer achieved. But writing a great case study can be difficult if you’ve never done it before or if it’s been a while. This guide will show you how to write an effective case study and provide real-world examples and templates that will keep readers engaged and support your business.
In this article, you’ll learn:
What is a case study?
How to write a case study, case study templates, case study examples, case study tools.
A case study is the detailed story of a customer’s experience with a product or service that demonstrates their success and often includes measurable outcomes. Case studies are used in a range of fields and for various reasons, from business to academic research. They’re especially impactful in marketing as brands work to convince and convert consumers with relatable, real-world stories of actual customer experiences.
The best case studies tell the story of a customer’s success, including the steps they took, the results they achieved and the support they received from a brand along the way. To write a great case study, you need to:
- Celebrate the customer and make them — not a product or service — the star of the story.
- Craft the story with specific audiences or target segments in mind so that the story of one customer will be viewed as relatable and actionable for another customer.
- Write copy that is easy to read and engaging so that readers will gain the insights and messages intended.
- Follow a standardised format that includes all of the essentials a potential customer would find interesting and useful.
- Support all of the claims for success made in the story with data in the forms of hard numbers and customer statements.
Case studies are a type of review but more in depth, aiming to show — rather than just tell — the positive experiences that customers have with a brand. Notably, 89% of consumers read reviews before deciding to buy and 79% view case study content as part of their purchasing process. When it comes to B2B sales, 52% of buyers rank case studies as an important part of their evaluation process.
Telling a brand story through the experience of a tried-and-true customer matters. The story is relatable to potential new customers as they imagine themselves in the shoes of the company or individual featured in the case study. Showcasing previous customers can help new ones see themselves engaging with your brand in the ways that are most meaningful to them.
Besides sharing the perspective of another customer, case studies stand out from other content marketing forms because they are based on evidence. Whether pulling from client testimonials or data-driven results, case studies tend to have more impact on new business because the story contains information that is both objective (data) and subjective (customer experience) — and the brand doesn’t sound too self-promotional.

Case studies are unique in that there’s a fairly standardised format for telling a customer’s story. But that doesn’t mean there isn’t room for creativity. It’s all about making sure that teams are clear on the goals for the case study — along with strategies for supporting content and channels — and understanding how the story fits within the framework of the company’s overall marketing goals.
Here are the basic steps to writing a good case study.
1. Identify your goal
Start by defining exactly who your case study will be designed to help. Case studies are about specific instances where a company works with a customer to achieve a goal. Identify which customers are likely to have these goals, as well as other needs the story should cover to appeal to them.
The answer is often found in one of the buyer personas that have been constructed as part of your larger marketing strategy. This can include anything from new leads generated by the marketing team to long-term customers that are being pressed for cross-sell opportunities. In all of these cases, demonstrating value through a relatable customer success story can be part of the solution to conversion.
2. Choose your client or subject
Who you highlight matters. Case studies tie brands together that might otherwise not cross paths. A writer will want to ensure that the highlighted customer aligns with their own company’s brand identity and offerings. Look for a customer with positive name recognition who has had great success with a product or service and is willing to be an advocate.
The client should also match up with the identified target audience. Whichever company or individual is selected should be a reflection of other potential customers who can see themselves in similar circumstances, having the same problems and possible solutions.
Some of the most compelling case studies feature customers who:
- Switch from one product or service to another while naming competitors that missed the mark.
- Experience measurable results that are relatable to others in a specific industry.
- Represent well-known brands and recognisable names that are likely to compel action.
- Advocate for a product or service as a champion and are well-versed in its advantages.
Whoever or whatever customer is selected, marketers must ensure that they have the permission of the company involved before getting started. Some brands have strict review and approval procedures for any official marketing or promotional materials that include their name. Acquiring those approvals in advance will prevent any miscommunication or wasted effort if there is an issue with their legal or compliance teams.
3. Conduct research and compile data
Substantiating the claims made in a case study — either by the marketing team or customers themselves — adds validity to the story. To do this, include data and feedback from the client that defines what success looks like. This can be anything from demonstrating return on investment (ROI) to a specific metric the customer was striving to improve. Case studies should prove how an outcome was achieved and show tangible results that indicate to the customer that your solution is the right one.
This step could also include customer interviews. Make sure that the people being interviewed are key stakeholders in the purchase decision or deployment and use of the product or service that is being highlighted. Content writers should work off a set list of questions prepared in advance. It can be helpful to share these with the interviewees beforehand so they have time to consider and craft their responses. One of the best interview tactics to keep in mind is to ask questions where yes and no are not natural answers. This way, your subject will provide more open-ended responses that produce more meaningful content.
4. Choose the right format
There are a number of different ways to format a case study. Depending on what you hope to achieve, one style will be better than another. However, there are some common elements to include, such as:
- An engaging headline
- A subject and customer introduction
- The unique challenge or challenges the customer faced
- The solution the customer used to solve the problem
- The results achieved
- Data and statistics to back up claims of success
- A strong call to action (CTA) to engage with the vendor
It’s also important to note that while case studies are traditionally written as stories, they don’t have to be in a written format. Some companies choose to get more creative with their case studies and produce multimedia content, depending on their audience and objectives. Case study formats can include traditional print stories, interactive web or social content, data-heavy infographics, professionally shot videos, podcasts and more.
5. Write your case study
We’ll go into more detail later about how exactly to write a case study, including templates and examples. Generally speaking, though, there are a few things to keep in mind when writing your case study.
- Be clear and concise. Readers want to get to the point of the story quickly and easily and they’ll be looking to see themselves reflected in the story right from the start.
- Provide a big picture. Always make sure to explain who the client is, their goals and how they achieved success in a short introduction to engage the reader.
- Construct a clear narrative. Stick to the story from the perspective of the customer and what they needed to solve instead of just listing product features or benefits.
- Leverage graphics. Incorporating infographics, charts and sidebars can be a more engaging and eye-catching way to share key statistics and data in readable ways.
- Offer the right amount of detail. Most case studies are one or two pages with clear sections that a reader can skim to find the information most important to them.
- Include data to support claims. Show real results — both facts and figures and customer quotes — to demonstrate credibility and prove the solution works.
6. Promote your story
Marketers have a number of options for distribution of a freshly minted case study. Many brands choose to publish case studies on their website and post them on social media. This can help support SEO and organic content strategies while also boosting company credibility and trust as visitors see that other businesses have used the product or service.
Marketers are always looking for quality content they can use for lead generation. Consider offering a case study as gated content behind a form on a landing page or as an offer in an email message. One great way to do this is to summarise the content and tease the full story available for download after the user takes an action.
Sales teams can also leverage case studies, so be sure they are aware that the assets exist once they’re published. Especially when it comes to larger B2B sales, companies often ask for examples of similar customer challenges that have been solved.
Now that you’ve learnt a bit about case studies and what they should include, you may be wondering how to start creating great customer story content. Here are a couple of templates you can use to structure your case study.
Template 1 — Challenge-solution-result format
- Start with an engaging title. This should be fewer than 70 characters long for SEO best practices. One of the best ways to approach the title is to include the customer’s name and a hint at the challenge they overcame in the end.
- Create an introduction. Lead with an explanation as to who the customer is, the need they had and the opportunity they found with a specific product or solution. Writers can also suggest the success the customer experienced with the solution they chose.
- Present the challenge. This should be several paragraphs long and explain the problem the customer faced and the issues they were trying to solve. Details should tie into the company’s products and services naturally. This section needs to be the most relatable to the reader so they can picture themselves in a similar situation.
- Share the solution. Explain which product or service offered was the ideal fit for the customer and why. Feel free to delve into their experience setting up, purchasing and onboarding the solution.
- Explain the results. Demonstrate the impact of the solution they chose by backing up their positive experience with data. Fill in with customer quotes and tangible, measurable results that show the effect of their choice.
- Ask for action. Include a CTA at the end of the case study that invites readers to keep in touch for more information, try a demo or learn more — to nurture them further in the marketing pipeline. What you ask of the reader should tie directly into the goals that were established for the case study in the first place.
Template 2 — Data-driven format
- Start with an engaging title. Make sure that you include a statistic or data point in the first 70 characters. Again, it’s best to include the customer’s name as part of the title.
- Create an overview. Share the customer’s background and a short version of the challenge they faced. Present the reason a particular product or service was chosen and feel free to include quotes from the customer about their selection process.
- Present data point 1. Isolate the first metric that the customer used to define success and explain how the product or solution helped to achieve this goal. Provide data points and quotes to substantiate the claim that success was achieved.
- Present data point 2. Isolate the second metric that the customer used to define success and explain what the product or solution did to achieve this goal. Provide data points and quotes to substantiate the claim that success was achieved.
- Present data point 3. Isolate the final metric that the customer used to define success and explain what the product or solution did to achieve this goal. Provide data points and quotes to substantiate the claim that success was achieved.
- Summarise the results. Reiterate the fact that the customer was able to achieve success thanks to a specific product or service. Include quotes and statements that reflect customer satisfaction and suggest they plan to continue using the solution.
- Ask for action. Include a CTA at the end of the case study that asks readers to keep in touch for more information, try a demo or learn more — to further nurture them in the marketing pipeline. Again, remember that this is where marketers can look to convert their content into action with the customer.
While templates are helpful, seeing a case study in action can also be a great way to learn. Here are some examples of how Adobe customers have experienced success.
Juniper Networks
One example is the Adobe and Juniper Networks case study , which puts the reader in the customer’s shoes. The beginning of the story quickly orients the reader so that they know exactly who the article is about and what they were trying to achieve. Solutions are outlined in a way that shows Adobe Experience Manager is the best choice and a natural fit for the customer. Along the way, quotes from the client are incorporated to help add validity to the statements. The results in the case study are conveyed with clear evidence of scale and volume using tangible data.

The story of Lenovo’s journey with Adobe is one that spans years of planning, implementation and roll-out. The Lenovo case study does a great job of consolidating all of this into a relatable journey that other enterprise organisations can see themselves taking, despite the project size. This case study also features descriptive headers and compelling visual elements that engage the reader and strengthen the content.
Tata Consulting
When it comes to using data to show customer results, this case study does an excellent job of conveying details and numbers in an easy-to-digest manner. Bullet points at the start break up the content while also helping the reader understand exactly what the case study will be about. Tata Consulting used Adobe to deliver elevated, engaging content experiences for a large telecommunications client of its own — an objective that’s relatable for a lot of companies.
Case studies are a vital tool for any marketing team as they enable you to demonstrate the value of your company’s products and services to others. They help marketers do their job and add credibility to a brand trying to promote its solutions by using the experiences and stories of real customers.
When you’re ready to get started with a case study:
- Think about a few goals you’d like to accomplish with your content.
- Make a list of successful clients that would be strong candidates for a case study.
- Keep in touch to the client to get their approval and conduct an interview.
- Gather the data to present an engaging and effective customer story.
Adobe can help
There are several Adobe products that can help you craft compelling case studies. Adobe Experience Platform helps you to collect data and deliver great customer experiences across every channel. Once you’ve created your case studies, Experience Platform will help you to deliver the right information to the right customer at the right time for maximum impact.
To learn more, watch the Adobe Experience Platform story .
Keep in mind that the best case studies are backed by data. That’s where Adobe Real-Time Customer Data Platform and Adobe Analytics come into play. With Real-Time CDP, you can gather the data you need to build a great case study and target specific customers to deliver the content to the right audience at the perfect moment.
Watch the Real-Time CDP overview video to learn more.
Finally, Adobe Analytics turns real-time data into real-time insights. It helps your business collect and synthesise data from multiple platforms to make more informed decisions and create the best case study possible.
Request a demo to learn more about Adobe Analytics.
https://business.adobe.com/blog/perspectives/b2b-ecommerce-10-case-studies-inspire-you
https://business.adobe.com/blog/basics/business-case
https://business.adobe.com/blog/basics/what-is-real-time-analytics
Chapter 9 - Incident Response

- Table of Contents
- Foreword II
- 1. How SRE Relates to DevOps
- Part I - Foundations
- 2. Implementing SLOs
- 3. SLO Engineering Case Studies
- 4. Monitoring
- 5. Alerting on SLOs
- 6. Eliminating Toil
- 7. Simplicity
- Part II - Practices
- 9. Incident Response
- 10. Postmortem Culture: Learning from Failure
- 11. Managing Load
- 12. Introducing Non-Abstract Large System Design
- 13. Data Processing Pipelines
- 14. Configuration Design and Best Practices
- 15. Configuration Specifics
- 16. Canarying Releases
- Part III - Processes
- 17. Identifying and Recovering from Overload
- 18. SRE Engagement Model
- 19. SRE: Reaching Beyond Your Walls
- 20. SRE Team Lifecycles
- 21. Organizational Change Management in SRE
- Appendix A. Example SLO Document
- Appendix B. Example Error Budget Policy
- Appendix C. Results of Postmortem Analysis
- About the Editors
Incident Response
By Jennifer Mace, Jelena Oertel, Stephen Thorne, and Arup Chakrabarti (PagerDuty) with Jian Ma and Jessie Yang
Everyone wants their services to run smoothly all the time, but we live in an imperfect world in which outages do occur. What happens when a not-so-ordinary, urgent problem requires multiple individuals or teams to resolve it? You are suddenly faced with simultaneously managing the incident response and resolving the problem.
Resolving an incident means mitigating the impact and/or restoring the service to its previous condition. Managing an incident means coordinating the efforts of responding teams in an efficient manner and ensuring that communication flows both between the responders and to those interested in the incident’s progress. Many tech companies, including Google, have adopted and adapted best practices for managing incidents from emergency response organizations, which have been using these practices for many years.
The basic premise of incident management is to respond to an incident in a structured way. Large-scale incidents can be confusing; a structure that teams agree on beforehand can reduce chaos. Formulating rules about how to communicate and coordinate your efforts before disaster strikes allows your team to concentrate on resolving an incident when it occurs. If your team has already practiced and familiarized themselves with communication and coordination, they don’t need to worry about these factors during an incident.
Setting up an incident response process doesn’t need to be a daunting task. There are a number of widely available resources that can provide some guidance, such as Managing Incidents in the first SRE Book. The basic principles of incident response include the following:
- Maintain a clear line of command.
- Designate clearly defined roles.
- Keep a working record of debugging and mitigation as you go.
- Declare incidents early and often.
This chapter shows how incident management is set up at Google and PagerDuty, and gives examples of where we got this process right and where we didn’t. The simple checklist in Putting Best Practices into Practice can help you get started on creating your own incident response practice, if you don’t already have one.
Incident Management at Google
Incident response provides a system for responding to and managing an incident. A framework and set of defined procedures allow a team to respond to an incident effectively and scale up their response. Google’s incident response system is based on the Incident Command System (ICS) .
Incident Command System
ICS was established in 1968 by firefighters as a way to manage wildfires. This framework provides standardized ways to communicate and fill clearly specified roles during an incident. Based upon the success of the model, companies later adapted ICS to respond to computer and system failures. This chapter explores two such frameworks: PagerDuty’s Incident Response process and Incident Management At Google ( IMAG ).
Incident response frameworks have three common goals, also known as the “three Cs” (3Cs) of incident management:
- Coordinate response effort.
- Communicate between incident responders, within the organization, and to the outside world.
- Maintain control over the incident response.
When something goes wrong with incident response, the culprit is likely in one of these areas. Mastering the 3Cs is essential for effective incident response.
Main Roles in Incident Response
The main roles in incident response are the Incident Commander (IC), Communications Lead (CL), and Operations or Ops Lead (OL). IMAG organizes these roles into a hierarchy: the IC leads the incident response, and the CL and OL report to the IC.
When disaster strikes, the person who declares the incident typically steps into the IC role and directs the high-level state of the incident. The IC concentrates on the 3Cs and does the following:
- Commands and coordinates the incident response, delegating roles as needed. By default, the IC assumes all roles that have not been delegated yet.
- Communicates effectively.
- Stays in control of the incident response.
- Works with other responders to resolve the incident.
The IC may either hand off their role to someone else and assume the OL role, or assign the OL role to someone else. The OL works to respond to the incident by applying operational tools to mitigate or resolve the incident.
While the IC and OL work on mitigating and resolving the incident, the CL is the public face of the incident response team. The CL’s main duties include providing periodic updates to the incident response team and stakeholders, and managing inquiries about the incident.
Both the CL and OL may lead a team of people to help manage their specific areas of incident response. These teams can expand or contract as needed. If the incident becomes small enough, the CL role can be subsumed back into the IC role.
Case Studies
The following four large-scale incidents illustrate how incident response works in practice. Three of these case studies are from Google, and the last is a case study from PagerDuty, which provides perspective on how other organizations use ICS-derived frameworks. The Google examples start with an incident that wasn’t managed effectively, and progress to incidents that were managed well.
Case Study 1: Software Bug—The Lights Are On but No One’s (Google) Home
This example shows how failing to declare an incident early on can leave a team without the tools to respond to an incident quickly and efficiently. While this incident was resolved without major calamity, early escalation would have produced a quicker, more organized response, and a better outcome.
Google Home is a smart speaker and home assistant that responds to voice commands. The voice commands interact with Google Home’s software, which is called Google Assistant.
Interacting with Google Home starts when a user says a hotword , a given phrase that triggers Google Assistant. Multiple users can use the same Google Home device by training the assistant to listen for a given hotword. The hotword model that identifies speakers is trained on the client, but the training data (i.e., the speaker recognition files) is stored on the server. The server handles bidirectional streaming of data. To handle overload during busy times, the server has a quota policy for Google Assistant. In order to protect servers from overly large request values, the quota limit is significantly higher than the baseline usage for Google Assistant on a given device.
A bug in Google Assistant version 1.88 caused speaker recognition files to be fetched 50 times more often than expected, exceeding this quota. Initially, Google Home users in the central United States experienced only small traffic losses. As the rollout increased progressively to all Google Home devices, however, users lost half of their requests during the weekend of June 3, 2017.
At 11:48 a.m. PST on Monday, May 22, Jasper, the developer on-call for Google Home, happened to be looking at the queries per second (QPS) graphs and noticed something strange: Google Assistant had been pinging training data every 30 minutes, instead of once per day as expected. He stopped the release of version 1.88, which had rolled out to 25% of users. He raised a bug—let’s call it bug 12345—with Google’s bug tracking system to explore why this was happening. On the bug, he noted that Google Assistant was pinging data 48 times a day, causing it to exceed its QPS capacity.
Another developer, Melinda, linked the issue to a previously reported bug, which we’ll call bug 67890: any time an app refreshed the device authentication and enrollment state, the speech processor restarted. This bug was slated to be fixed after the version 1.88 release, so the team requested a temporary increase in quota for the model to mitigate the overload from extra queries.
The version 1.88 release was started again and continued to roll out, reaching 50% of users by Wednesday, May 31. Unfortunately, the team later learned that bug 67890, while responsible for some extra traffic, was not the actual root cause of the more frequent fetches that Jasper had noticed.
That same morning, customers started reporting an issue to Google’s support team: any time someone said “OK Google” (or any other hotword to activate Google Home), the device responded with an error message. This issue prevented users from giving commands to Google Assistant. The team began to investigate what could be causing the errors that users reported. They suspected quota issues, so they requested another increase to the quota, which seemed to mitigate the problem.
Meanwhile, the team continued to investigate bug 12345 to see what was triggering the errors. Although the quota connection was established early in the debugging process, miscommunication between the client and server developers had led developers down the wrong path during troubleshooting, and the full solution remained out of reach.
The team also puzzled over why Google Assistant’s traffic kept hitting quota limits. The client and server developers were confused by client-side errors that didn’t seem to be triggered by any problems on the server side. The developers added logging to the next release to help the team understand the errors better, and hopefully make progress in resolving the incident.
By Thursday, June 1, users reported that the issue had been resolved. No new issues were reported, so the version 1.88 release continued to roll out. However, the root cause of the original issue had not yet been identified.
By early Saturday morning, June 3, the version 1.88 release rollout surpassed 50%. The rollout was happening on a weekend, when developers were not readily available. The team had not followed the best practice of performing rollouts only during business days to ensure developers are around in case something goes wrong.
When the version 1.88 release rollout reached 100% on Saturday, June 3, the client once more hit server limits for Google Assistant traffic. New reports from customers started coming in. Google employees reported that their Google Home devices were throwing errors. The Google Home support team received numerous customer phone calls, tweets, and Reddit posts about the issue, and Google Home’s help forum displayed a growing thread discussing the issue. Despite all the user reports and feedback, the bug wasn’t escalated to a higher priority.
On Sunday, June 4, as the number of customer reports continued to increase, the support team finally raised the bug priority to the highest level. The team did not declare an incident, but continued to troubleshoot the issue via “normal” methods, using the bug tracking system for communication. The on-call developer noticed error rates in one of the datacenter clusters and pinged SRE, asking them to drain it. At the same time, the team submitted another request for a quota increase. Afterward, an engineer on the developer team noticed the drain had pushed errors into other cells, which provided additional evidence of quota issues. At 3:33 p.m., the developer team manager increased the quota for Google Assistant once again, and the impact on users stopped. The incident was over. The team identified the root cause (see the previous “Context” section) shortly thereafter.
Some aspects of incident handling went really well, while others had room for improvement.
First, the developers rallied on the weekend and provided valuable input to resolve the issue. This was both good and bad. While the team valued the time and effort these individuals contributed over the weekend, successful incident management shouldn’t rely on heroic efforts of individuals. What if the developers had been unreachable? At the end of the day, Google supports a good work-life balance—engineers shouldn’t be tapped during their free time to fix work-related problems. Instead, we should have conducted rollouts during business hours or organized an on-call rotation that provided paid coverage outside of business hours.
Next, the team worked to mitigate the issue. Google always aims to first stop the impact of an incident, and then find the root cause (unless the root cause just happens to be identified early on). Once the issue is mitigated, it’s just as important to understand the root cause in order to prevent the issue from happening again. In this case, mitigation successfully stopped the impact on three separate occasions, but the team could only prevent the issue from recurring when they discovered the root cause. After the first mitigation, it would have been better to postpone the rollout until the root cause was fully determined, avoiding the major disruption that happened over the weekend.
Finally, the team did not declare an incident when problems first appeared. Our experience shows that managed incidents are resolved faster. Declaring an incident early ensures that:
- Miscommunication between the client and server developers is prevented.
- Root-cause identification and incident resolution occur sooner.
- Relevant teams are looped in earlier, making external communications faster and smoother.
Centralized communication is an important principle of the IMAG protocol. For example, when disaster strikes, SREs typically gather in a “war room.” The war room can be a physical location like a conference room, or it can be virtual: teams might gather on an IRC channel or Hangout. The key here is to gather all the incident responders in one place and to communicate in real time to manage—and ultimately resolve—an incident.
Case Study 2: Service Fault—Cache Me If You Can
The following incident illustrates what happens when a team of experts tries to debug a system with so many interactions that no single person can grasp all the details. Sound familiar?
Kubernetes is an open source container management system built collaboratively by many companies and individual contributors. Google Kubernetes Engine, or GKE, is a Google-managed system that creates, hosts, and runs Kubernetes clusters for users. This hosted version operates the control plane, while users upload and manage workloads in the way that suits them best.
When a user first creates a new cluster, GKE fetches and initializes the Docker images their cluster requires. Ideally, these components are fetched and built internally so we can validate them. But because Kubernetes is an open source system, new dependencies sometimes slip in through the cracks.
One Thursday at 6:41 a.m. PST, London’s on-call SRE for GKE, Zara, was paged for CreateCluster prober failures across several zones. No new clusters were being successfully created. Zara checked the prober dashboard and saw that failures were above 60% for two zones. She verified this issue was affecting user attempts to create new clusters, though traffic to existing clusters was not affected. Zara followed GKE’s documented procedure and declared an incident at 7:06 a.m.
Initially, four people were involved in the incident:
- Zara, who first noticed the problem, and was therefore the designated default Incident Commander
- Two of Zara’s teammates
- Rohit, the customer support engineer paged by the incident procedure
Since Rohit was based in Zurich, Zara (the IC) opened a GKE Panic IRC channel where the team could debug together. While the other two SREs dug into monitoring and error messages, Zara explained the outage and its impact to Rohit. By 7:24 a.m., Rohit posted a notice to users that CreateCluster was failing in the Europe-West region. This was turning into a large incident.
Between 7 a.m. and 8:20 a.m., Zara, Rohit, and the others worked on troubleshooting the issue. They examined cluster startup logs, which revealed an error:
They needed to determine which part of the certificate creation failed. The SREs investigated the network, resource availability, and the certificate signing process. All seemed to work fine separately. At 8:22 a.m., Zara posted a summary of the investigation to the incident management system, and looked for a developer who could help her.
Thankfully, GKE had a developer on-call who could be paged for emergencies. The developer, Victoria, joined the channel. She asked for a tracking bug and requested that the team escalate the issue to the infrastructure on-call team.
It was now 8:45 a.m. The first Seattle SRE, Il-Seong, arrived at the office, lightly caffeinated and ready for the day. Il-Seong was a senior SRE with many years of experience in incident response. When he was informed about the ongoing incident, he jumped in to help. First, Il-Seong checked the day’s release against the timing of the alerts, and determined that the day’s release did not cause the incident. He then started a working document 1 to collect notes. He suggested that Zara escalate the incident to the infrastructure, cloud networking, and compute engine teams to possibly eliminate those areas as root causes. As a result of Zara’s escalation, additional people joined the incident response:
- The developer lead for GKE nodes
- Cloud Networking on-call
- Compute Engine on-call
- Herais, another Seattle SRE
At 9:10 a.m., the incident channel had a dozen participants. The incident was 2.5 hours old, with no root cause and no mitigation. Communication was becoming a challenge. Normally, on-call handover from London to Seattle occurred at 10 a.m., but Zara decided to hand over incident command to Il-Seong before 10 a.m., since he had more experience with IMAG.
As Incident Commander, Il-Seong set up a formal structure to address the incident. He then designated Zara as Ops Lead and Herais as Communications (Comms) Lead. Rohit remained the External Communications Lead. Herais immediately sent an “all hands on deck” email to several GKE lists, including all developer leads, and asked experts to join the incident response.
So far, the incident responders knew the following:
- Cluster creation failed where nodes attempted to register with the master.
- The error message indicated the certificate signing module as the culprit.
- All cluster creation in Europe was failing; all other continents were fine.
- No other GCP services in Europe were seeing network or quota problems.
Thanks to the call for all hands on deck, Puanani, a GKE Security team member, joined the effort. She noticed the certificate signer was not starting. The certificate signer was trying to pull an image from DockerHub, and the image appeared to be corrupted. Victoria (the on-call GKE developer) ran Docker’s pull command for the image in two geographic locations. It failed when it ran on a cluster in Europe and succeeded on a cluster in the US. This indicated that the European cluster was the problem. At 9:56 a.m., the team had identified a plausible root cause.
Because DockerHub was an external dependency, mitigation and root causing would be especially challenging. The first option for mitigation was for someone at Docker to quickly fix the image. The second option was to reconfigure the clusters to fetch the image from a different location, such as Google Container Registry (GCR), Google’s secure image hosting system. All the other dependencies, including other references to the image, were located in GCR.
Il-Seong assigned owners to pursue both options. He then delegated a team to investigate fixing the broken cluster. Discussion became too dense for IRC, so detailed debugging moved to the shared document, and IRC became the hub for decision making.
For the second option, pushing a new configuration meant rebuilding binaries, which took about an hour. At 10:59 a.m., when the team was 90% done rebuilding, they discovered another location that was using the bad image fetch path. In response, they had to restart the build.
While the engineers on IRC worked on the two mitigation options, Tugay, an SRE, had an idea. Instead of rebuilding the configuration and pushing it out (a cumbersome and risky process), what if they intercepted Docker’s pull requests and substituted the response from Docker with an internal cached image? GCR had a mirror for doing precisely this. Tugay reached out to contacts on GCR’s SRE team, and they confirmed that the team could set --registry-mirror= https://mirror.gcr.io on the Docker configuration. Tugay started setting up this functionality and discovered that the mirror was already in place!
At 11:29 a.m., Tugay reported to IRC that these images were being pulled from the GCR mirror, not DockerHub . At 11:37 a.m., the Incident Commander paged GCR on-call. At 11:59 a.m., GCR on-call purged the corrupt image from their European storage layer. By 12:11 p.m., all European zones had fallen to 0% error.
The outage was over. All that remained was cleanup, and writing a truly epic postmortem.
CreateCluster had failed in Europe for 6 hours and 40 minutes before it was fixed. In IRC, 41 unique users appeared throughout the incident, and IRC logs stretched to 26,000 words. The effort spun up seven IMAG task forces at various times, and as many as four worked simultaneously at any given time. On-calls were summoned from six teams, not including those from the “all hands on deck” call. The postmortem contained 28 action items.
The GKE CreateCluster outage was a large incident by anyone’s standards. Let’s explore what went well, and what could have been handled better.
What went well? The team had several documented escalation paths and was familiar with incident response tactics. Zara, the GKE on-call, quickly verified that the impact was affecting actual customers. She then used an incident management system prepared beforehand to bring in Rohit, who communicated the outage to customers.
What could have been handled better? The service itself had some areas of concern. Complexity and dependence on specialists were problematic. Logging was insufficient for diagnosis, and the team was distracted by the corruption on DockerHub, which was not the real issue.
At the beginning of the incident, the Incident Commander didn’t put a formal incident response structure in place. While Zara assumed this role and moved the conversation to IRC, she could have been much more proactive in coordinating information and making decisions. As a result, a handful of first responders pursued their own investigations without coordination. Il-Seong put a formal incident response structure in place two hours after the first page.
Finally, the incident revealed a gap in GKE’s disaster readiness: the service didn’t have any early generic mitigations that would reduce user pain. Generic mitigations are actions that first responders take to alleviate pain, even before the root cause is fully understood. For example, responders could roll back a recent release when an outage is correlated with the release cycle, or reconfigure load balancers to avoid a region when errors are localized. It’s important to note that generic mitigations are blunt instruments and may cause other disruptions to the service. However, while they may have broader impact than a precise solution, they can be put in place quickly to stop the bleeding while the team discovers and addresses the root cause.
Let’s look at the timeline of this incident again to see where a generic mitigation might have been effective:
- 7 a.m. (Assessed impact). Zara confirmed that users were affected by the outage.
- 9:56 a.m. (Found possible cause). Puanani and Victoria identified a rogue image.
- 10:59 a.m. (Bespoke mitigation). Several team members worked on rebuilding binaries to push a new configuration that would fetch images from a different location.
- 11:59 a.m. (Found root cause and fixed the issue). Tugay and GCR on-call disabled GCR caching and purged a corrupt image from their European storage layer.
A generic mitigation after step 2 (found possible cause) would have been very useful here. If the responders had rolled back all images to a known good state once they discovered the issue’s general location, the incident would have been mitigated by 10 a.m. To mitigate an incident, you don’t have to fully understand the details—you only need to know the location of the root cause. Having the ability to mitigate an outage before its cause is fully understood is crucial for running robust services with high availability.
In this case, the responders would have benefited from some sort of tool that facilitated rollbacks. Mitigation tools do take engineering time to develop. The right time to create general-purpose mitigation tools is before an incident occurs, not when you are responding to an emergency. Browsing postmortems is a great way to discover mitigations and/or tools that would have been useful in retrospect, and build them into services so that you can better manage incidents in the future.
It’s important to remember that first responders must prioritize mitigation above all else , or time to resolution suffers. Having a generic mitigation in place, such as rollback and drain, speeds recovery and leads to happier customers. Ultimately, customers do not care whether or not you fully understand what caused an outage. What they want is to stop receiving errors.
With mitigation as top priority, an active incident should be addressed as follows:
- Assess the impact of the incident.
- Mitigate the impact.
- Perform a root-cause analysis of the incident.
- After the incident is over, fix what caused the incident and write a postmortem.
Afterward, you can run incident response drills to exercise the vulnerabilities in the system, and engineers can work on projects to address these vulnerabilities.
Case Study 3: Power Outage—Lightning Never Strikes Twice…Until It Does
The previous examples showed what can go wrong when you don’t have good incident response strategies in place. The next example illustrates an incident that was successfully managed. When you follow a well-defined and clear response protocol, you can handle even rare or unusual incidents with ease.
Power grid events, such as lightning strikes, cause the power coming into a datacenter facility to vary wildly. Lightning strikes affecting the power grid are rare, but not unexpected. Google protects against sudden, unexpected power outages with backup generators and batteries, which are well tested and known to work in these scenarios.
Many of Google’s servers have a large number of disks attached to them, with the disks located on a separate tray above or below the server. These trays have their own uninterruptible power supply (UPS) battery. When a power outage occurs, the backup generators activate but take a few minutes to start. During this period, the backup batteries attached to the servers and disk trays provide power until the backup generators are fully running, thereby preventing power grid events from impacting datacenter operation.
In mid-2015, lightning struck the power grid near a Google datacenter in Belgium four times within two minutes. The datacenter’s backup generators activated to supply power to all the machines. While the backup generators were starting up, most of the servers ran on backup batteries for a few minutes.
The UPS batteries in the disk trays did not swap power usage to the backup batteries on the third and fourth lightning strikes because the strikes were too closely spaced. As a result, the disk trays lost power until the backup generators kicked in. The servers did not lose power, but were unable to access the disks that had power cycled.
Losing a large number of disk trays on persistent disk storage resulted in read and write errors for many virtual machine (VM) instances running on Google Compute Engine (GCE). The Persistent Disk SRE on-call was immediately notified of these errors. Once the Persistent Disk SRE team established the impact, a major incident was declared and announced to all affected parties. The Persistent Disk SRE on-call assumed the role of Incident Commander.
After an initial investigation and communication between stakeholders, we established that:
- Each machine that lost a disk tray because of the temporary power outage needed to be rebooted.
- While waiting for the reboot, some customer VMs had trouble reading and writing to their disks.
- Any host that had both a disk tray and customer VMs could not simply be “rebooted” without losing the customer VMs that hadn’t been affected. Persistent Disk SRE asked GCE SRE to migrate unaffected VMs to other hosts.
The Persistent Disk SRE’s primary on-call retained the IC role, since that team had the best visibility into customer impact.
Operations team members were tasked with the following objectives:
- Safely restore power to use grid power instead of backup generators.
- Restart all machines that were not hosting VMs.
- Coordinate between Persistent Disk SRE and GCE SRE to safely move VMs away from the affected machines before restarting them.
The first two objectives were clearly defined, well understood, and documented. The datacenter ops on-call immediately started working to safely restore power, providing regular status reports to the IC. Persistent Disk SRE had defined procedures for restarting all machines not hosting virtual machines. A team member began restarting those machines.
The third objective was more vague and wasn’t covered by any existing procedures. The Incident Commander assigned a dedicated operations team member to coordinate with GCE SRE and Persistent Disk SRE. These teams collaborated to safely move VMs away from the affected machines so the affected machines could be rebooted. The IC closely monitored their progress and realized that this work called for new tools to be written quickly. The IC organized more engineers to report to the operations team so they could create the necessary tools.
The Communications Lead observed and asked questions about all incident-related activities, and was responsible for reporting accurate information to multiple audiences:
- Company leaders needed information about the extent of the problem, and assurance that the problem was being addressed.
- Teams with storage concerns needed to know when their storage would be fully available again.
- External customers needed to be proactively informed about the problem with their disks in this cloud region.
- Specific customers who had filed support tickets needed more information about the problems they were seeing, and advice on workarounds and timelines.
After we mitigated the initial customer impact, we needed to do some follow-up, such as:
- Diagnosing why the UPS used by the disk trays failed, and making sure that it doesn’t happen again.
- Replacing the batteries in the datacenter that failed.
- Manually clearing “stuck” operations caused by losing so many storage systems simultaneously.
Post-incident analysis revealed that only a small number of writes—the writes pending on the machines that lost power during the incident—weren’t ever written to disk. Since Persistent Disk snapshots and all Cloud Storage data are stored in multiple datacenters for redundancy, only 0.000001% of data from running GCE machines was lost, and only data from running instances was at risk.
By declaring the incident early and organizing a response with clear leadership, a carefully managed group of people handled this complex incident effectively.
The Incident Commander delegated the normal problems of restoring power and rebooting servers to the appropriate Operations Lead. Engineers worked on fixing the issue and reported their progress back to the Operations Lead.
The more complex problem of meeting the needs of both GCE and Persistent Disk required coordinated decision making and interaction among multiple teams. The Incident Commander made sure to assign appropriate operations team members from both teams to the incident, and worked directly with them to drive toward a solution. The Incident Commander wisely focused on the most important aspect of the incident: addressing the needs of the impacted customers as quickly as possible.
Case Study 4: Incident Response at PagerDuty
by Arup Chakrabarti of PagerDuty
PagerDuty has developed and refined our internal incident response practices over the course of several years. Initially, we staffed a permanent, company-wide Incident Commander and dedicated specific engineers per service to take part in incident response. As PagerDuty grew to over 400 employees and dozens of engineering teams, our Incident Response processes also changed. Every few months, we take a hard look at our processes, and update them to reflect business needs. Nearly everything we have learned is documented at https://response.pagerduty.com. Our Incident Response processes are purposefully not static; they change and evolve just as our business does.
Major incident response at PagerDuty
Typically, small incidents require only a single on-call engineer to respond. When it comes to larger incidents, we place heavy emphasis on teamwork. An engineer shouldn’t feel alone in high-stress and high-impact scenarios. We use the following techniques to help promote teamwork:
Participating in simulation exercises
- One way we teach teamwork is by participating in Failure Friday . PagerDuty drew inspiration from Netflix’s Simian Army to create this program. Originally, Failure Friday was a manual failure injection exercise aimed at learning more about the ways our systems could break. Today, we also use this weekly exercise to recreate common problems in production and incident response scenarios.
- Before Failure Friday starts, we nominate an Incident Commander (typically, a person training to become an IC). They are expected to behave and act like a real IC while conducting failure injection exercises. Throughout the drill, subject-matter experts use the same processes and vernacular they would use during an actual incident. This practice both familiarizes new on-call engineers with incident response language and processes and provides more seasoned on-call engineers with a refresher.
Playing time-bound simulation games
- While Failure Friday exercises go a long way toward training engineers on different roles and processes, they can’t fully replicate the urgency of actual major incidents. We use simulation games with a time-bound urgency to capture that aspect of incident response.
- “Keep Talking and Nobody Explodes” is one game we’ve leveraged heavily. It requires players to work together to defuse bombs within time limits. The stressful and communication-intensive nature of the game forces players to cooperate and work together effectively.
Learning from previous incidents
- Learning from previous incidents helps us respond better to major incidents in the future. To this end, we conduct and regularly review postmortems.
- PagerDuty’s postmortem process involves open meetings and thorough documentation. By making this information easily accessible and discoverable, we aim to reduce the resolution time of future incidents, or prevent a future incident from happening altogether.
- We also record all of the phone calls involved in a major incident so we can learn from the real-time communication feed.
Let’s look at a recent incident in which PagerDuty had to leverage our incident response process. The incident occurred on October 6, 2017, and lasted more than 10 hours, but had very minimal customer impact.
- 7:53 p.m. A member of the PagerDuty SRE team was alerted that PagerDuty internal NTP servers were exhibiting clock drift. The on-call SRE validated that all automated recovery actions had been executed, and completed the mitigation steps in relevant runbooks. This work was documented in the SRE team’s dedicated Slack channel.
- 8:20 p.m. A member of PagerDuty Software Team A received an automated alert about clock drift errors in their services. Software Team A and the SRE team worked toward resolving the problem.
- 9:17 p.m. A member of PagerDuty Software Team B received an automated alert about clock drift errors on their services. The engineer from Team B joined the Slack channel where the issue was already being triaged and debugged.
- 9:49 p.m. The SRE on-call declared a major incident and alerted the Incident Commander on-call.
For the next eight hours, the response team worked on addressing and mitigating the issue. When the procedures in our runbooks didn’t resolve the issue, the response team started trying new recovery options in a methodical manner.
During this time, we rotated on-call engineers and the IC every four hours. Doing so encouraged engineers to get rest and brought new ideas into the response team.
- 5:33 a.m. The on-call SRE made a configuration change to the NTP servers.
- 6:13 a.m. The IC validated that all services had recovered with their respective on-call engineers. Once validation was complete, the IC shut off the conference call and Slack channel and declared the incident complete. Given the wide impact of the NTP service, a postmortem was warranted. Before closing out the incident, the IC assigned the postmortem analysis to the SRE team on-call for the service.
Tools used for incident response
Our Incident Response processes leverage three main tools:
- We store all of our on-call information, service ownership, postmortems, incident metadata, and the like, in PagerDuty. This allows us to rapidly assemble the right team when something goes wrong.
- We maintain a dedicated channel (#incident-war-room) as a gathering place for all subject-matter experts and Incident Commanders. The channel is used mostly as an information ledger for the scribe, who captures actions, owners, and timestamps.
Conference calls
- When asked to join any incident response, on-call engineers are required to dial in to a static conference call number. We prefer that all coordination decisions are made in the conference call, and that decision outcomes are recorded in Slack. We found this was the fastest way to make decisions. We also record every call to make sure that we can recreate any timeline in case the scribe misses important details.
While Slack and conference calls are our communication channels of choice, you should use the communication method that works best for your company and its engineers.
At PagerDuty, how we handle incident response relates directly to the success of the company. Rather than facing such events unprepared, we purposefully prepare for incidents by conducting simulation exercises, reviewing previous incidents, and choosing the right tools to help us be resilient to any major incident that may come our way.
Putting Best Practices into Practice
We’ve seen examples of incidents that were handled well, and some that were not. By the time a pager alerts you to a problem, it’s too late to think about how to manage the incident. The time to start thinking about an incident management process is before an incident occurs. So how do you prepare and put theory into practice before disaster strikes? This section provides some recommendations.
Incident Response Training
We highly recommend training responders to organize an incident so they have a pattern to follow in a real emergency. Knowing how to organize an incident, having a common language to use throughout the incident, and sharing the same expectations reduce the chance of miscommunication.
The full Incident Command System approach may be more than you need, but you can develop a framework for handling incidents by selecting the parts of the incident management process that are important to your organization. For example:
- Let on-calls know they can delegate and escalate during an incident.
- Encourage a mitigation-first response.
- Define Incident Commander, Communications Lead, and Operations Lead roles.
You can adapt and summarize your incident response framework, and create a slide deck to present to new team members. We’ve learned that people are more receptive to incident response training when they can connect the theory of incident response to actual scenarios and concrete actions. Therefore, be sure to include hands-on exercises and share what happened in past incidents, analyzing what went well and what didn’t go so well. You might also consider using external agencies that specialize in incident response classes and training.
Prepare Beforehand
In addition to incident response training, it helps to prepare for an incident beforehand. Use the following tips and strategies to be better prepared.
Decide on a communication channel
Decide and agree on a communication channel (Slack, a phone bridge, IRC, HipChat, etc.) beforehand—no Incident Commander wants to make this decision during an incident. Practice using it so there are no surprises. If possible, pick a communications channel the team is already familiar with so that everyone on the team feels comfortable using it.
Keep your audience informed
Unless you acknowledge that an incident is happening and actively being addressed, people will automatically assume nothing is being done to resolve the issue. Similarly, if you forget to call off the response once the issue has been mitigated or resolved, people will assume the incident is ongoing. You can preempt this dynamic by keeping your audience informed throughout the incident with regular status updates. Having a prepared list of contacts (see the next tip) saves valuable time and ensures you don’t miss anyone.
Think ahead about how you’ll draft, review, approve, and release public blog posts or press releases. At Google, teams seek guidance from the PR team. Also, prepare two or three ready-to-use templates for sharing information, making sure the on-call knows how to send them. No one wants to write these announcements under extreme stress with no guidelines. The templates make sharing information with the public easy and minimally stressful.
Prepare a list of contacts
Having a list of people to email or page prepared beforehand saves critical time and effort. In Case Study 2: Service Fault—Cache Me If You Can , the Comms Lead made an “all hands on deck” call by sending an email to several GKE lists that were prepared beforehand.
Establish criteria for an incident
Sometimes it’s clear that a paging issue is truly an incident. Other times, it’s not so clear. It’s helpful to have an established list of criteria for determining if an issue is indeed an incident. A team can come up with a solid list of criteria by looking at past outages, taking known high-risk areas into consideration.
In summary, it’s important to establish common ground for coordination and communication when responding to incidents. Decide on ways to communicate the incident, who your audience is, and who is responsible for what during an incident. These guidelines are easy to set up and have high impact on shortening the resolution time of an incident.
The final step in the incident management process is practicing your incident management skills. By practicing during less critical situations, your team develops good habits and patterns of behavior for when lightning strikes—figuratively and literally. After introducing the theory of incident response through training, practice ensures that your incident response skills stay fresh.
There are several ways to conduct incident management drills. Google runs company-wide resilience testing (called Disaster Recovery Testing, or DiRT; see Kripa Krishnan’s article “Weathering the Unexpected” 2 ), in which we create a controlled emergency that doesn’t actually impact customers. Teams respond to the controlled emergency as if it were a real emergency. Afterward, the teams review the emergency response procedures and discuss what happened. Accepting failure as a means of learning, finding value in gaps identified, and getting our leadership on board were key to successfully establishing the DiRT program at Google. On a smaller scale, we practice responding to specific incidents using exercises like Wheel of Misfortune (see “Disaster Role Playing” in Site Reliability Engineering ).
You can also practice incident response by intentionally treating minor problems as major ones requiring a large-scale response. This lets your team practice with the procedures and tools in a real-world situation with lower stakes.
Drills are a friendly way of trying out new incident response skills. Anyone on your team who could get swept into incident response—SREs, developers, and even customer support and marketing partners—should feel comfortable with these tactics.
To stage a drill, you can invent an outage and allow your team to respond to the incident. You can also create outages from postmortems, which contain plenty of ideas for incident management drills. Use real tools as much as possible to manage the incident. Consider breaking your test environment so the team can perform real troubleshooting using existing tools.
All these drills are far more useful if they’re run periodically. You can make drills impactful by following up each exercise with a report detailing what went well, what didn’t go well, and how things could have been handled better. The most valuable part of running a drill is examining their outcomes, which can reveal a lot about any gaps in incident management. Once you know what they are, you can work toward closing them.
Be prepared for when disaster strikes. If your team practices and refreshes your incident response procedures regularly, you won’t panic when the inevitable outage occurs.
The circle of people you need to collaborate with during an incident expands with the size of the incident. When you’re working with people you don’t know, procedures help create the structure you need to quickly move toward a resolution. We strongly recommend establishing these procedures ahead of time when the world is not on fire. Regularly review and iterate on your incident management plans and playbooks.
The Incident Command System is a simple concept that is easily understood. It scales up or down according to the size of the company and the incident. Although it’s simple to understand, it isn’t easy to implement, especially in the middle of an incident when panic suddenly overtakes you. Staying calm and following the response structure during an emergency takes practice, and practice builds “muscle memory.” This gives you the confidence you’ll need for a real emergency.
We strongly recommend carving out some time in your team’s busy schedule to practice incident management on a regular basis. Secure support from leadership for dedicated practice time, and make sure they understand how incident response works in case you need to involve them in a real incident. Disaster preparedness can shave off valuable minutes or hours from response time and gives you a competitive edge. No company gets it right all the time—learn from your mistakes, move on, and do better the next time.
1 When three or more people work on an incident, it’s useful to start a collaborative document that lists working theories, eliminated causes, and useful debugging information, such as error logs and suspect graphs. The document preserves this information so it doesn’t get lost in the conversation.
2 Kripa Krishan, “Weathering the Unexpected,” Communications of the ACM 10, no. 9 (2012), https://queue.acm.org/detail.cfm?id=2371516 .
Chapter 8 - On-Call
Chapter 10 - Postmortem Culture: Learning from Failure
Copyright © 2018 Google, Inc. Published by O'Reilly Media, Inc. Licensed under CC BY-NC-ND 4.0
Workplace Incidents Case Study
Introduction.
The following case study presents an analysis of a workplace incident at [Your Company Name], a company specializing in automotive parts production. This study aims to dissect the incident's causes, the company's immediate response, and the subsequent measures taken to prevent future occurrences. The focus is not only on the technical and procedural aspects but also on the human and organizational dimensions of workplace safety. Understanding such incidents is crucial for developing more resilient and safer work environments.
Incident Description
The incident at [Your Company Name]'s main warehouse, known for producing automotive parts, occurred on [July 15th, 2050]. This section provides a detailed description of the event, including a timeline of the incident, the immediate causes, and the subsequent chain of events.
Timeline of Events
Immediate causes.
Mechanical Failure: A snapped chain in the conveyor belt mechanism led to the system's failure.
Overloaded Shelving: The shelving units, with a maximum capacity of 500 kg, were overloaded with about [700 kg], exceeding their limit and compromising their stability.
Response to the Incident
Following the incident, the response was immediate and in accordance with the company’s emergency protocols. This section details the actions taken immediately after the incident to ensure safety and provide necessary aid.
Emergency Procedures Activated
The emergency alarm was activated at [10:18 AM], leading to an automated shutdown of critical machinery in the facility.
The warehouse supervisor conducted a prompt headcount at the designated assembly point outside the warehouse.
Emergency services, including fire and ambulance services, were contacted at [10:20 AM].
Medical Attention and First Aid
First aid was administered on-site to three employees who sustained minor injuries. One employee with a suspected concussion was transported to a hospital for further evaluation.
Evacuation and Safety Measures
The evacuation of the warehouse was completed efficiently within [5 minutes] of the incident.
Emergency services conducted a safety inspection of the area to ensure no further hazards.
Continuous communication was maintained with all employees and stakeholders during and after the incident, providing updates and reassurances.
Investigation and Analysis
A thorough investigation was initiated immediately following the incident at [Your Company Name] to determine the root causes and contributing factors. This comprehensive analysis involved examining the mechanical systems, interviewing employees, and reviewing safety protocols.
Root Cause Analysis
The investigation revealed several critical factors leading to the incident:
Conveyor Belt Maintenance: It was found that the conveyor belt had not undergone routine maintenance checks as prescribed, leading to the wear and tear of the chain.
Shelving Unit Overloading: The shelving units were routinely overloaded beyond their capacity, a practice that had become common due to increased production demands.
Contributing Factors
Several additional factors contributed to the severity of the incident:
Lack of Regular Inspections: Regular safety inspections were not adequately enforced, leading to overlooked hazards.
Inadequate Employee Training: Employees were not sufficiently trained in recognizing and reporting potential safety hazards.
Communication Breakdown: There was a lack of effective communication channels for reporting equipment issues and safety concerns.
Preventative Measures
In response to the findings of the investigation, [Your Company Name] has implemented a series of preventative measures to mitigate the risk of similar incidents in the future.
Equipment Maintenance and Safety Checks
Regular Maintenance Schedules: A strict maintenance schedule has been established for all critical machinery, including conveyor belts and shelving units.
Safety Audits: Regular safety audits will be conducted to identify and rectify potential hazards in the workplace.
Training and Awareness Programs
Safety Training: Comprehensive safety training programs have been introduced for all employees, focusing on equipment handling and hazard recognition.
Emergency Response Drills : Regular emergency response drills will be conducted to ensure employees are prepared for various types of emergencies.
Policy Revisions and Implementation
Revised Safety Protocols: Updated safety protocols have been implemented, emphasizing the importance of adherence to equipment weight limits and maintenance schedules.
Reporting Mechanism: A streamlined reporting mechanism has been established for employees to report safety concerns or equipment malfunctions without fear of reprisal.
Through these measures, [Your Company Name] aims to foster a safer working environment and prevent future incidents. Regular reviews and updates of these measures will be conducted to ensure their effectiveness and relevance.
Employee Support and Recovery
Following the incident at [Your Company Name], significant attention was devoted to supporting and aiding the recovery of employees impacted by the event. This section outlines the initiatives undertaken to ensure the well-being of the workforce and to foster a supportive work environment.
Counseling and Support Services
Recognizing the emotional and psychological impact of the incident, [Your Company Name] implemented several measures:
On-Site Counseling: Professional counselors were made available on-site for [two weeks] following the incident to provide immediate psychological support.
Long-Term Counseling Services: Arrangements were made with a local mental health clinic to provide long-term counseling services for employees who required ongoing support.
Review of Workplace Practices
A comprehensive review of workplace practices was conducted with a focus on enhancing safety culture and employee well-being:
Safety Culture Assessment: An external agency was hired to assess the existing safety culture and recommend improvements.
Employee Feedback: Employees were encouraged to provide feedback on their workplace experience and suggest improvements through anonymous surveys.
Rehabilitation and Reintegration
For employees physically injured in the incident, specific measures were implemented to facilitate their rehabilitation and reintegration into the workplace:
Physical Rehabilitation: Employees with physical injuries received company-sponsored physiotherapy and rehabilitation services.
Workplace Adjustments: Adjustments and accommodations were made in the workplace to support the return of injured employees, such as modified workstations and flexible work hours.
Ongoing Monitoring and Support
To ensure continued support, [Your Company Name] established a long-term monitoring and support system:
Health and Wellness Programs: Programs focusing on physical health, mental well-being, and stress management were introduced.
Regular Check-Ins: Regular check-ins with affected employees were scheduled to monitor their recovery and address any ongoing needs or concerns.
Through these initiatives, [Your Company Name] aims to provide a comprehensive support system for its employees, prioritizing their physical and mental well-being and ensuring a safe and supportive return to work.
The incident at [Your Company Name] serves as a poignant reminder of the critical importance of workplace safety and the multi-faceted approach required to ensure it. The investigation revealed key areas of concern, including equipment maintenance, employee training, and safety culture. The company's response, though swift and effective in addressing immediate safety concerns, highlighted the need for a more proactive approach to risk management and employee well-being.
The preventative measures, employee support, and recovery initiatives undertaken post-incident represent a significant step forward in [Your Company Name]'s commitment to creating a safe and supportive work environment. These actions not only address the specific issues that led to the incident but also lay the groundwork for a more robust safety culture.
Key takeaways from this incident include:
The Necessity of Regular Maintenance and Safety Checks: Ensuring that equipment is regularly maintained and that safety checks are a routine part of operations is essential to prevent mechanical failures.
Importance of Employee Training and Awareness: Regular training in safety protocols and emergency procedures is crucial for preventing incidents and ensuring effective responses when they do occur.
Building a Responsive and Supportive Work Culture: Establishing channels for open communication, feedback, and reporting of safety concerns is vital in fostering a culture where safety is a shared responsibility.
Comprehensive Support for Affected Employees: Providing immediate and long-term support to employees, both physically and psychologically, is key to their recovery and the overall health of the workforce.
This case study underscores the importance of continuous improvement in workplace safety practices. [Your Company Name]'s experience serves as a valuable lesson for similar industries, emphasizing that safety is an ongoing journey rather than a fixed destination.
Health & Safety Templates @ Template.net
Manual Handling Risk Assessment Template
Occupational Health Assessment Template
Risk Assessment Template
Site Safety Inspection Checklist Template
Accident Report Form Template
Simple Construction Safety Checklist Template
Safety Incident Log Template
Safety Training Program Template
Contractor Safety Agreement Template
Workplace Safety Inspection Report Template
Professional Employee Safety Handbook Template
OHS Policy Template
Environmental Safety Plan Template
Workplace Safety Training Plan Template
Health & Safety Management Policy Template
Workplace Hazard Report Template
Safety Performance Report Template
OHS Safety Program Manual Template
Construction Site Safety Briefing Invitation Card Template
Health and Wellness Seminar Invitation Card Template
Workplace Safety Training Workshop Invitation Card Template
Work-Life Balance and Stress Management Brochure Template
Office Safety Procedures Brochure Template
Traffic Safety Flyer Template
Safety Flyer Template
Simple Safety Certificate Template
Safety Certificate Template
Safety Management Certificate Template
Child Care Safety Certificate Template
Occupational Health and Safety Certificate Template
Occupational Health and Safety Care Certificate Template
Safety Award Certificate Template
Health and Wellness Program Announcement Poster Template
Mental Health Support Services Pamphlet Template
Fire Safety Awareness Event Invitation Card Template
Health & Safety Awareness Monitoring Plan Template
Health & Safety Awareness Risk Analysis Template
Health & Safety Communication Leadership Guide Template
Health & Safety Communication Assessment Report Template
Health & Safety Awareness Impact Study Template
Health & Safety Communication User Guide Template
Health & Safety Training & Awareness Manual Template
Health & Safety Communication SWOT Analysis Template
Health & Safety Awareness Campaign Study Template
Health & Safety SOP for Communication Template
Health & Safety Communication Protocol Development Template
Health & Safety Campaign Research Report Template
Health & Safety Awareness Campaign Portfolio Template
Health & Safety Awareness Procedure Manual Template
Strategic Health & Safety Communication Plan Template
Register for our webinar with Meric Bloch to learn how to effectively and fairly interview the implicated employee during a workplace investigation.
- Resource Center
Incident Response Plan Template
Complete the form below to get your free template.
Organizations need to need to develop an incident response plan that defines workplace incidents, offers examples, outlines employee responsibilities and describes incident response procedures. This template includes editable sections and sample text you can include in your organization's document.
Download this free Incident Response Plan template to help guide employees in the event of a workplace incident.
This template includes:
- Information about workplace incidents
- A complete table of contents
- Five sections with headers, instructions and sample text
Download Template
Related resources, holiday party memo template, whistleblower policy template.
IMAGES
VIDEO
COMMENTS
EDIT THIS INCIDENT REPORT. Step 1. Take immediate action. Employees of your organization should notify their manager or another member of the company's leadership committee as soon as an incident occurs-regardless of the nature of the event (whether it be an accident, illness, injury or near miss).
Incident Case Study. I. Introduction: In this case study, we examine the response of [Your Company Name] to a significant data breach. The case highlights the importance of having a robust incident response plan in place to mitigate the impact of such incidents and protect sensitive information. II. Background:
The Doc breaks down an incident reporting process that's easy to navigate. These documents can be used for incident tracking, incident analysis, and incident prevention purposes. Download This Template. 2. ClickUp Incident Action Plan Template. ClickUp Incident Action Plan Template.
3 How to Write an Incident Report. 4 Incident Report Examples. 4.1 Injury Incident Report Example. 4.2 Forklift Accident Report Sample. 4.3 Fall Incident Report Sample. 4.4 Hand Injury Incident Report Sample. 4.5 Exposure Incident Report Sample. 4.6 First Aid Incident Report Sample. 5 Incident Report Form Templates.
An incident response plan template is a structured approach for identifying, responding to and managing cybersecurity incidents or data breaches. It emphasizes a proactive approach, ensuring that all team members understand their roles and responsibilities in the event of an incident.
Using the scenario above, the first section of your report would begin to look something like this: In our incident report example, we took advantage of adding photo evidence to better illustrate the environment where the incident took place. Notice that the photo attached had an annotation.
Select your inicent report type (injury, near miss, property damage, theft, or equipment failure) and location, date, and time. Input your incident description and an incident photo. Tag the person involved and witnesses from your team. Complete root cause analysis. Log your incident.
Step 2: Perform an Effective Incident Root Cause Analysis for Resolution. Using the timeline of events, you can then start conducting a root cause analysis (RCA). An RCA is the process of identifying the underlying causes that led to an event.
An event is any occurrence that you can observe, verify, and document. An incident, on the other hand, is an event that has a negative effect on an organization and its security. Whether intentional or unintentional, these incidents impact a company's ability to accomplish its mission. The CIS incident response template consists of the following:
Incident Report Templates. Venngage's incident report templates offer a systematic and comprehensive approach to documenting and analyzing critical events. Whether for workplace incidents, accidents, or emergencies, these templates provide a structured framework for recording essential details, ensuring accuracy and consistency in reporting.
With incident report templates on hand, you'll be able to document any accidents when they happen, and your team can work to improve its protocols for a safer workplace. If you're looking for additional incident report templates that we didn't cover in this article, be sure to check out more examples of incident reports in our app store.
A well-written workplace incident report protects both the worker and the company. Almost 3 million non-fatal workplace incidents were reported by private industry employers in 2019 and over 888,000 in the public sector, according to the Bureau of Labor Statistics. Thirty-eight per cent of women have been sexually harassed at work.
This incident report template is powered by Dashpivot project management software. Easily edit or add form fields with simple drag-and-drop functionality and customise the report to your liking. Access and use your incident report from anywhere - on laptop, computer, mobile or tablet. Take and add supporting attachments to your report in the ...
Download this Workplace Incidents Case Study Template Design in Word, Google Docs, PDF Format. Easily Editable, Printable, Downloadable. Analyze and learn from past incidents with the Workplace Incidents Case Study Template from Template.net. Editable and customizable, this template facilitates in-depth examination of workplace incidents.
If so, you've come to the right place. The Incident Report Template is a free download that contains four incident report templates. Each template reflects the type of questions that need to be answered based on the incident being reported. This incident report template pack helps HR, investigators and other departments capture important ...
This is an example of how the Cause Mapping process can be applied to a specific incident. In this case the Hindenburg crash is captured as an example of the Cause Mapping method. The three steps are 1) Define the problem, 2) Conduct the analysis and 3) Identify the best solutions…. Root cause analysis examples demonstrate how Cause Mapping ...
Incident Investigation Case StudiesIn groups of two or three, determine what the incident was, the direct cause of the incident, the indirect causes of the incident, and what corrective actions should be put in place to prevent. ents from reoccurring.Case study 1A lift truck operator received extensive acid burns to his face and hands when a 50 ...
Here are a couple of templates you can use to structure your case study. Template 1 — Challenge-solution-result format. Start with an engaging title. This should be fewer than 70 characters long for SEO best practices. One of the best ways to approach the title is to include the customer's name and a hint at the challenge they overcame in ...
The Incident Commander wisely focused on the most important aspect of the incident: addressing the needs of the impacted customers as quickly as possible. Case Study 4: Incident Response at PagerDuty. by Arup Chakrabarti of PagerDuty PagerDuty has developed and refined our internal incident response practices over the course of several years.
The following case study presents an analysis of a workplace incident at [Your Company Name], a company specializing in automotive parts production. This study aims to dissect the incident's causes, the company's immediate response, and the subsequent measures taken to prevent future occurrences.
This template includes editable sections and sample text you can include in your organization's document. Download this free Incident Response Plan template to help guide employees in the event of a workplace incident. This template includes: Information about workplace incidents. A complete table of contents. Five sections with headers ...